 8 hours ago
2
8 hours ago
2
KT가 자체 개발한 대규모언어모델(LLM) ‘믿:음’의 새로운 버전을 들고나왔다. 2023년 10월 첫 번째 모델 이후 1년7개월 만이다. 후발주자란 약점을 극복하기 위해 오픈소스 전략도 택했다. 개인과 기업, 공공기관 누구나 제약 없이 상업적으로 활용할 수 있다. KT가 공백을 깨고 새 AI 모델을 내놓자 일각에선 인공지능 전환(AX)을 테마로 ‘통신 대장주’로 급부상한 KT가 소버린 AI(인공지능)의 대표 주자 격인 네이버와 ‘AI 대장주’ 왕관을 놓고 본격적인 혈전에 뛰어들었다는 분석도 나온다.
◇한국형 예의범절 이해하는 ‘한국형 AI’
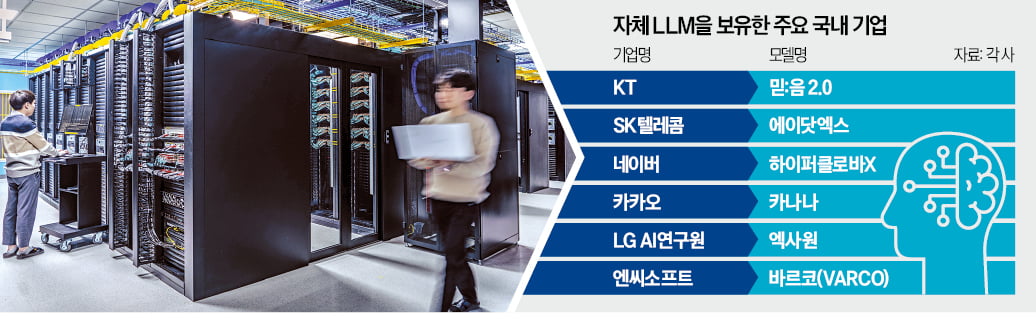
KT는 3일 기자간담회를 열고 새로운 LLM ‘믿:음 2.0’을 공개했다. 한국의 사회적 맥락과 관용 표현, 예의범절 등 고유의 언어·문화적 특성을 담아낸 것이 특징이다. 한국어 데이터를 수집하고 정제하는 과정 모두 KT의 자체 기술로 이뤄졌다. 고려대 민족문화연구원, 각종 공공기관, ‘K-데이터 얼라이언스’ 등을 통해 데이터를 수집했다.
KT는 믿:음 2.0으로 기업 간 거래(B2B) 시장은 물론 소비자 대상(B2C) 시장도 공략하겠다는 포부를 내비쳤다. 신동훈 KT 상무는 “KT의 최종 목표는 다양한 규모의 모델을 고객 요구 맞춤형으로 제공하는 ‘AI 오케스트레이션’ 서비스 구축”이라고 말했다.
SK텔레콤도 이날 LLM 모델 ‘에이닷엑스(A.X) 4.0’을 선보였다. 알리바바의 오픈소스 LLM을 기반으로 한국 특화 데이터를 학습시켰다. KT와 마찬가지로 오픈소스 형태로 AI 모델을 공개했다.
KT와 SK텔레콤이 나란히 신규 AI 모델을 공개한 배경에는 정부 정책의 변화가 있다. 이재명 정부는 출범 직후부터 독자적 AI 모델 개발을 전폭적으로 지원한다는 입장을 밝힌 데다 ‘독자 AI 파운데이션 모델 프로젝트’에 속도를 내고 있다. 통신사들도 자체 개발 AI 모델로 공공사업 수주에 뛰어들 준비에 나섰다는 분석이 나온다.
이와 관련해 KT는 정부의 AI 모델 프로젝트에 적극적으로 참여하겠다는 의사를 밝혔다. 신 상무는 “KT의 ‘한국형 AI를 만들자’는 철학과 정부 프로젝트의 성격이 맞닿아 있다”며 “믿:음을 내놓기 위해 축적한 한국형 데이터와 KT의 독자 AI 개발 노하우가 큰 경쟁력이 될 것”이라고 강조했다.
◇MS와 믿:음 ‘투트랙’ 전략
KT는 그동안 마이크로소프트(MS)와 손잡고 한국형 AI를 개발해왔다. MS가 최대주주인 오픈AI의 ‘GPT-4o’를 기반으로 한국적 AI 모델을 만들어 AX 시장을 공략하겠다는 계획이다. MS와의 협업이 부각되면서 KT가 자체 AI 모델 개발에 소홀하다는 지적도 나왔다.
KT는 ‘투 트랙’ 전략을 세웠다고 강조했다. MS와 개발하는 모델은 대형 고객을 위한 엔터프라이즈형으로, 믿:음은 경량·맞춤형 솔루션으로 키우겠다는 것이다. 글로벌 솔루션을 원하는 기업 고객에 MS의 모델을 설계해 제안하고, 공공기관이나 동남아시아처럼 소버린 AI 구축을 원하는 고객을 위해선 자체 개발 모델을 제안하는 방식이다.
KT는 2023년 AI 개발에 나서며 자체 개발 AI 모델에 집중했다. 국내 산학연이 함께 모델을 개발하고 성과를 공유하는 ‘AI 원팀’도 구성했다. 매개변수(파라미터) 2000억 개 규모 모델을 개발했지만 미국 빅테크가 천문학적인 투자를 앞세워 기술 격차를 벌리면서 KT는 MS와 손잡는 전략을 택했다. 동시에 자체 개발 역량도 키웠다. 정부 사업은 자체 AI 개발 능력을 갖춘 기업에 유리하다는 판단에서다. KT 관계자는 “MS와의 협력 모델보다 믿:음 2.0을 먼저 공개한 것도 새 정부의 AI 프로젝트에 ‘매력 어필’을 할 수 있을 것이라고 판단했기 때문”이라고 설명했다.
최지희 기자 mymasaki@hankyung.com
![LB인베, 일본 진출…日 최대 IT개발자 HR 기업에 투자 [고은이의 VC 투자노트]](https://img.hankyung.com/photo/202507/01.41014115.1.jpg)







![[속보]李대통령, G7 참석차 내일 출국…“주요국 정상과 양자회담 조율”](https://dimg.donga.com/wps/NEWS/IMAGE/2025/06/15/131807427.2.jpg)




 English (US) ·
English (US) · 