 13 hours ago
4
13 hours ago
4

요즘 반도체 업계에서는 인공신경망장치(NPU)를 주목하는 분들이 많습니다. GPU로 세계 인공반도체(AI) 반도체 시장을 '씹어먹은' 엔비디아의 대항마가 될 것이라는 인식 때문인데요.
특히 한국에서는 퓨리오사 AI, 리벨리온, 딥엑스 등 스타트업들이 큰 기대를 받고 있습니다. 이재명 대통령도 대선 후보 시절 퓨리오사 AI를 찾을 정도로 AI 반도체에 애정을 가지고 있죠.
다만 일각에선 궁금증이 증폭되기도 합니다. 이들이 진짜로 엔비디아의 아성을 무너뜨릴 수준에 올라온 걸까. 당장 AI 서버에 들어갈 만한 성능을 가진 걸까.
취재를 통해 AI 업계에서 느껴진 '냉정하고' 객관적인 시선들을 모아서 토종 NPU 업체가 내세운 데이터를 딱 한꺼풀만 더 벗겨보겠습니다.
퓨리오사AI, 실전 AI 서버에서 정말 가능성 있을까
최근 NPU 업계에 정말 반가운 소식이 있었죠. LG AI연구원이 이달 발표한 '엑사원 4.0' AI 모델을 구동하는 데이터센터에 퓨리오사 AI의 NPU가 공급된다는 소식이었습니다.
백준호 퓨리오사AI 대표도 엑사원 4.0이 발표되는 'LG AI 토크 콘서트 2025'에 등장해 퓨리오사 AI 칩 '레니게이드(RNGD)'를 소개했습니다. 그간 LG와 협력한 히스토리를 설명하면서 말이죠.
그런데 AI 업계에서 퓨리오사AI의 발표 내용에 대해 아주 '냉정하게' 평가하는 목소리가 하나 있었습니다. 아래 슬라이드에 관한 내용입니다. 지금부터 아주 약간만 더 깊게 들어갑니다.

백 대표는 이 발표에서 레니게이드의 연산 성능에 대해 소개했습니다. 저는 여기서 '토큰(token)'에 대해 조금 더 자세히 이야기해보려고 합니다.
토큰이란 건 거대언어모델(LLM)에서 잘게 쪼갠 단어입니다. 예컨대 "저는 강해령입니다." 라는 문장에서는 "저는" "강해령" "입니다" 등 3개의 토큰이 나오는 거죠.
그럼 이제 오른쪽 표를 다시 보겠습니다. 작게 적힌 32K라는 작은 숫자는 인풋길이(input length)를 뜻합니다. 우선 K는 1000이니까, 3만2000이고요.
3만 2000개 토큰을 NPU에 던져주고 사용자의 질문에 대한 답을 찾아보라고 시켰더니, 4.5초만에 첫번째 토큰을 꺼내기 시작해 매초 50토큰을 생성하는(TPS=50)의 답을 정리해냈다는 설명입니다.
여기까지는 좋습니다. 그런데 AI 과학자들이 질문을 던지는 건 그 다음입니다. 아주 중요한 조건이 빠졌기 때문입니다. '배치 사이즈'에 관한 이야기입니다.
LLM 기업들은 나만의 과외선생님은 아닙니다. 모든 사람들에게 서비스를 해야 하죠. 그래서 AI 칩도 딱 한 사람의 한 가지 질문만을 받지는 않습니다. 세계 전역의 챗GPT 사용자들이 저마다의 사진을 들고 찾아와 '지브리 스타일로 바꿔줘'를 외친 것처럼 다양한 질문을 받고 답을 해줘야 합니다.
그걸 위해 필수적으로 따져봐야 하는 조건이 '배치 사이즈(batch size)'입니다. AI 칩이 32K의 육중한 토큰 꾸러미를 동시에 몇개 처리할 수 있는지를 보는 겁니다. 정말 쉬운 비유를 하면요. 10명이 동시에 3만 2000 토큰(A4지 약 40장) 분량의 책을 가져와서 AI 칩에게 "이거 좀 해석해달라"고 하면 배치 사이즈가 10입니다. 100명이 찾아오면 100이고요.
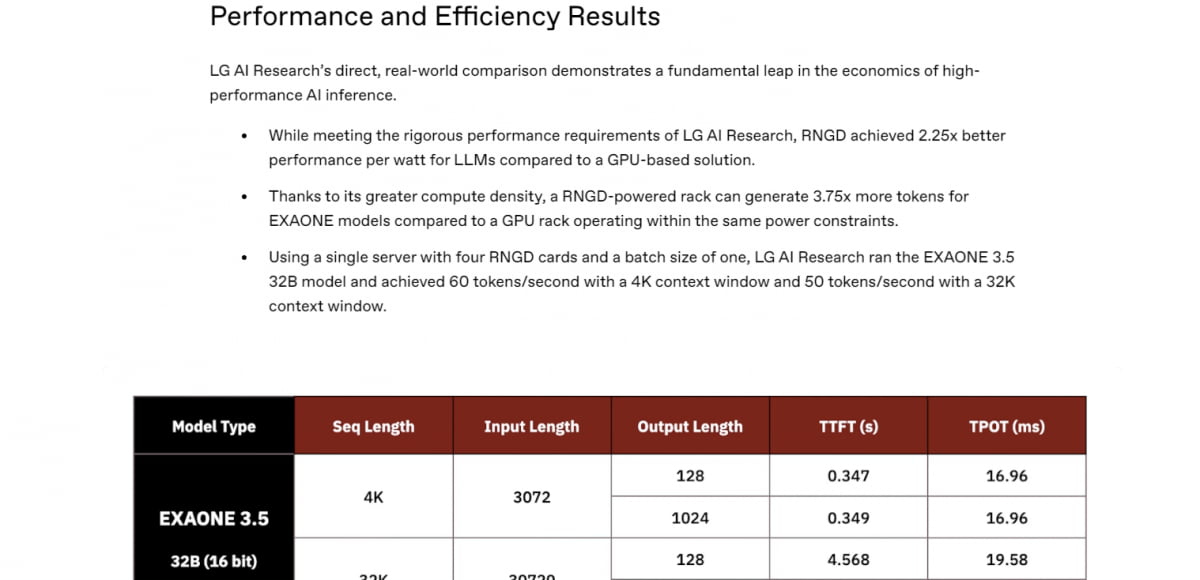
퓨리오사의 LG 엑사원 행사 발표에서는 이 조건이 나타나 있지 있습니다. 회사의 이 건에 대한 공식 문건을 찾아봤더니, 레니게이드 칩 4개를 배치 사이즈 조건을 '1'로 두고 테스트했다는 기록이 있습니다. 버스에 손님이 한 명 태우고 성능을 테스트했다는 이야기죠.
퓨리오사AI는 엔비디아 'A100'과의 성능 비교를 많이 합니다. 그런데 LLM 구현을 위해 A100을 써본 사람들의 말이나 각종 자료를 종합해보면요. 물론 쓰임새와 조건이 천차만별이라 배치 사이즈 설정도 제각각이지만, 단일 A100에서 배치사이즈를 128로도 설정할 수 있고 이때 TPS는 500~600까지 기록됩니다. 토큰 양이 배치사이즈 1로 설정한 퓨리오사 테스트 기록의 10배 수준이나 차이날 수 있다는 얘기입니다. 이정도 수치는 나와야 실전 LLM에 대응할 수 있는 칩이 될 수 있다는 분석입니다.
업계에서는 "배치 당 연산 능력을 아무리 끌어올렸다고 해도 크기를 1로 두고 연산하면 NPU의 효율성이 너무 떨어지고, LLM을 서비스할 수 없는 수준"이라고 설명합니다. TPU를 만드는 구글도, 어센드를 만드는 화웨이도 AI칩 논문에서 이 조건은 자주 명시하고 있습니다.
그래서 전문가들은 궁금해합니다. 퓨리오사는 왜 배치 사이즈를 1로 둔 실험결과만 공개한 걸까. 실전용 AI 서버까지 적용할 수 있는 성능에는 아직까지 자신이 없어서가 아닌가. 이런 물음이 업계 곳곳에서 제기되다보니 '퓨리오사는 아직 복수의 배치 사이즈를 가져갈 수 없다'는 루머까지 돌고 있습니다.
만약 퓨리오사AI가 공개한 성능대로 데이터센터에 적용된다면 클라우드 서비스를 운영하는 회사들이 큰 효율성 하락을 경험하게 될 것이라는 분석도 나옵니다. 엔비디아 칩 하나로 해결될 데이터 연산이 5~6개의 레니게이드 NPU가 있어야 가능하고, 공간과 전력이 몇 배는 더 들 것이기 때문이죠.

배치사이즈는 한 개의 예시입니다. 여기서부터 더 알고 싶은 부분들이 팽창하기 시작합니다.
레니게이드 8개로 한 개 서버를 구축했을 때 엔비디아 A100보다 전력 효율성이 2.3배 정도 나아졌다고 하는데, 그렇다면 A100에는 어떤 기준을 적용했는가.
△A100을 몇장 썼을 때인지 △어떤 네트워크 환경에서 배치 사이즈는 동일한 조건인지, 어떤 프레임워크를 썼는지 등 각종 조건을 세밀하고 투명하게 공개하기를 원하는 이들이 많습니다.
엑사원 4.0을 만든 LG AI 연구원 쪽을 취재해보면 우선 내부에서는 레니게이드의 배치 사이즈를 자사 LLM 모델에 알맞게 조절한 상태에서 테스트를 진행했다고 합니다. 8개월의 테스트 과정에서 "쓸만한 결과를 얻었다"는 평가가 나왔다고 합니다. 대외 공개된 자료와 평가에 비해서는 긍정적인 결과입니다.
다만 아직 양산품 구매 결정은 이뤄지지 않은 것으로 알려졌습니다. 지금 활용하고 있는 엔비디아 칩 외에 퓨리오사AI, AMD, 인텔, 리벨리온 장치들을 모두 검토하고 있는데 퓨리오사AI 제품이 우선 순위에 있는 건 맞지만 실전 도입까지는 아직 확정되지 않은 상황이라는 겁니다.
토종 NPU, 다양하고 공평한 조건에서 엔비디아 칩과 비교한 걸까
공개된 데이터를 조금 더 객관적이고 냉정하게 따져볼 필요가 있지만, 퓨리오사AI는 그래도 데이터가 투명한 편이라는 견해도 있습니다. 토종 AI 칩 회사들이 다양한 조건을 가리고 투자자들을 설득하거나, 대중들에게 제품을 소개하는 경우가 반도체 씬에서 빈번하게 일어난다는 제보를 취재 중 여러 번 받습니다.

예를 들면 또다른 토종 NPU 회사죠. 리벨리온도 예시를 들어보겠습니다. 현재 양산된 제품 중 가장 최첨단 제품인 '아톰 맥스'는 엔비디아 GPU인 L40S와 비교한 자료를 공식적으로 공개했는데요.
물론 L40S가 AI 추론 분야에서 쓰이고 있고 리벨리온이 비슷한 영역에 도전하고 있고, 두 칩 모두 메모리를 HBM이 아닌 GDDR을 활용한다는 점에서 비교군으로 설정한 것은 합리적입니다.
다만 이 엔비디아 주력인 A100 ·H100 등에 비해 정말 소비자의 선택을 받고 있는 '비교해볼 만한 칩'인지, GDDR 메모리의 한계 속에서 과연 아톰맥스 '전성비(전력대비성능)'의 우월함을 증명할 때 쓰일 수 있는 칩인지 한번 따져볼 필요가 있습니다. (L40S는 A100, H100 품귀현상이 극에 달했던 2022년~2023년에 엔비디아가 GPU 유통을 늘리기 위해 다급히 제작된 칩이라는 히스토리가 있습니다.)
아울러 이 회사의 자료 역시 L40S과의 스펙 비교가 어떤 기준으로 어떻게 이뤄졌는지에 대해 명확하게 설명돼있지 않은 점이 아쉬움을 줍니다.
또다른 칩 설계회사 A 업체는 NPU를 주력으로 2년 내 100배 가까운 매출 성장을 목표로 뒀다고 소개하고 있는데, 현재 이곳은 인력 이동에 대한 소문이 무성하고, 칩에 대한 구체적인 데이터를 들을 수 있는 경로가 제한적이라는 평가에서 자유롭지 못합니다.
국내 AI 반도체 업계 전반적으로 아직까지 소프트웨어 기술이 부족하다는 점도 꽤 많이 제기된 고질적 문제입니다. 엔비디아가 전세계를 장악하게 된 결정적 계기인 '쿠다(CUDA)' 같은 칩 동작 소프트웨어 기술이 무르익지 않았다는 건 이미 업계 내외에서 주지하고 있는 점이죠. 서버 업체들의 선택을 받기 위해서는 칩의 완성도 외에도 아직 많은 과정이 남았고 오랜 시간이 필요하다는 것을 방증하고 있습니다.
우리나라 토종 AI 칩 시장이 가라앉기를 바라면서 이 기사를 준비한 것은 아닙니다. 이들은 성공해야 합니다. AI 칩은 하루이틀 만에 뚝딱 나오는 것이 아닙니다. 뚝심있고 끈기있는 지원과 투자가 필요하고, 국민적인 응원과 관심이 있어야 할 수있는 일입니다.
다만 대통령까지 나서서 산업에 정조준을 하고 있는 만큼, 현실적이고 투명한 데이터 평가 및 공유, 이를 발판으로 한 열린 생태계가 조성돼야 앞으로 더욱더 발전할 가능성이 커진다는 업계의 메시지는 참고할 만 합니다.
AI 반도체는 국가의 명운을 가르는 아주 중요한 산업이 됐습니다. 차근차근, 솔직하고 담대한 오픈 생태계 속에서 한국의 기업들이 기술 패권 전쟁에서 큰 역할을 하기 바라면서 글 마칩니다. 감사합니다.
강해령 기자 hr.kang@hankyung.com




![한화생명 만나는 T1, '레전드 올킬' 도전한다 [이주현의 로그인 e스포츠]](https://img.hankyung.com/photo/202508/01.41288973.1.jpg)

![한은, 기준금리 연 2.50% 동결...집값, 가계대출 불안에 인하 유보 [HK영상]](https://img.hankyung.com/photo/202507/ZN.41075682.1.jpg)


![“로젠버그 차도가 없어, 복귀 불투명”…사실상 시즌아웃, 끝없는 키움 선발 고민 [SD 고척 브리핑]](https://dimg.donga.com/wps/SPORTS/IMAGE/2025/07/06/131945683.1.jpg)
!["韓 떠나는 K애니 인재들… 정부·기업 과감한 지원 나서야"[만났습니다]②](https://spnimage.edaily.co.kr/images/Photo/files/NP/S/2025/07/PS25071800014.jpg)





 English (US) ·
English (US) · 