멀티턴 대화에서 LLM의 이해와 한계
연구 목적
주요 발견
실험 방법
개선 방향
결론
멀티턴 대화에서 LLM의 한계
 1 week ago
8
1 week ago
8
Related

미국에서 한 달에 $432로 살아가는 방법
3 hours ago
0
HTTPS 사이트에 더 이상 구식 인증서를 사용하지 않는 이유
4 hours ago
0
OpenAI: PostgreSQL를 다음 단계로 확장하기
10 hours ago
2
Linux/Android 성능분석 솔루션 - Guider 3.9.9 릴리즈!
11 hours ago
2
내가 직접 만든 오디오 플레이어
11 hours ago
2
지구에는 서로 반대쪽에 두 개의 만조 융기(High-tide bulges)가 존재하는가?
11 hours ago
1
당신의 사람들을 찾으세요
11 hours ago
1
게임을 넘어 현실까지 배우는 AI: 존 카맥의 현실 기반 강화학습 도전
11 hours ago
1
Popular

김문수, 배현진에 “미스 가락시장” 발언 놓고 논란
1 week ago
84
Gmail to SQLite
1 week ago
72
21 GB/s 속도의 AMD 9950X에서 SIMD를 활용한 CSV 파싱
1 week ago
68

“챗GPT도 아니고 6만쪽 어떻게 다 읽나…책임 묻겠다”…민주 초선들, 조희대 탄핵 예고
3 weeks ago
48
![“뭉클했다” 친정팀 환영 영상 지켜 본 김하성의 소감 [MK현장]](https://pimg.mk.co.kr/news/cms/202504/26/news-p.v1.20250426.d92247f59a8b45a6b118c0f6ea5157ef_R.jpg)
“뭉클했다” 친정팀 환영 영상 지켜 본 김하성의 소감 [MK현장]
4 weeks ago
46
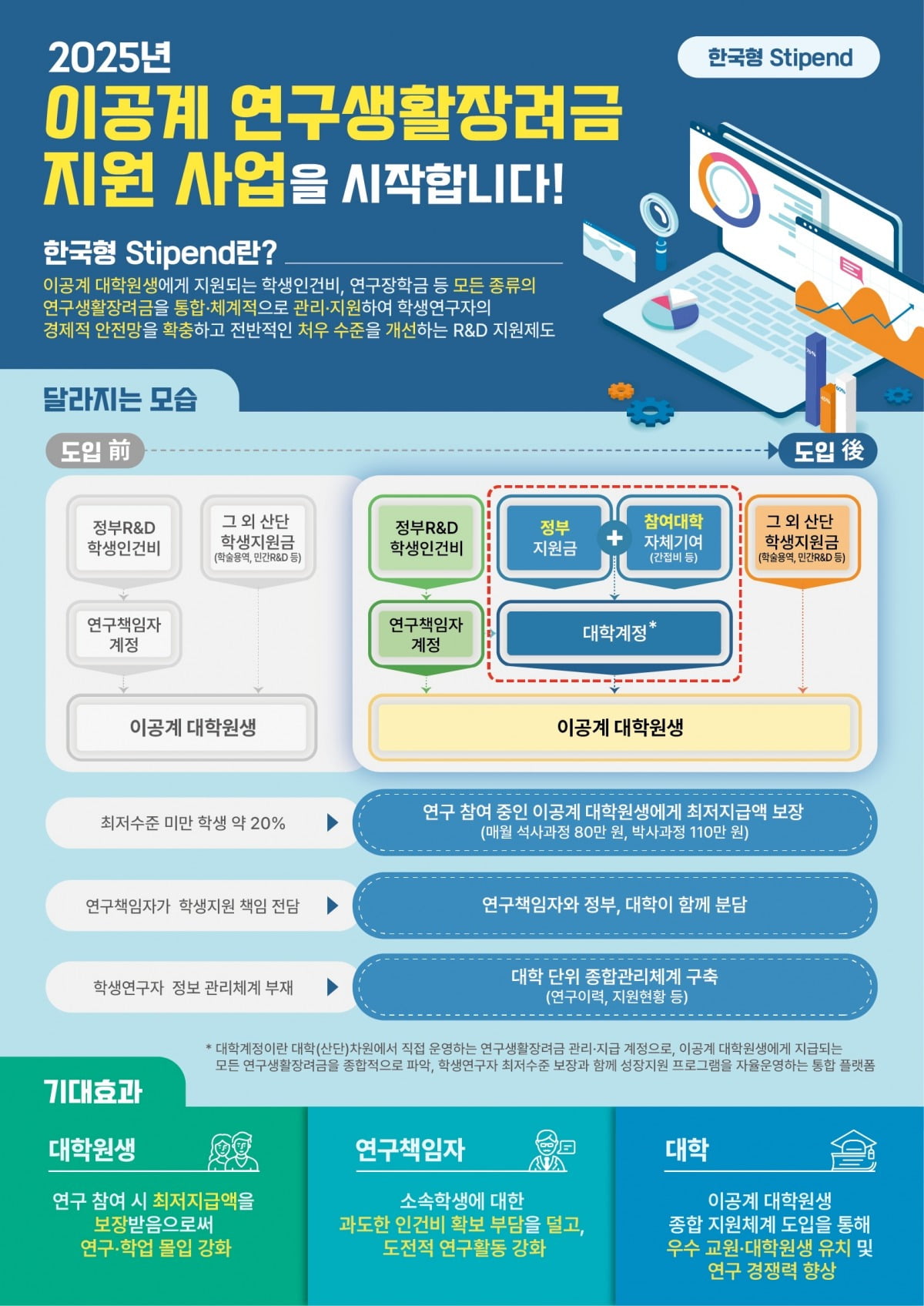
이공계 대학원생, 월 110만원 받는다…'한국형 스타이펜드' 첫걸음
4 weeks ago
46
Cloth 웹 시뮬레이터
3 weeks ago
43


Maintaining Security Material with SAP Cloud Integration
3 weeks ago
33

교황 선출 비밀투표를 OTT로…판돈 260억 몰린 '콘클라베' 생중계
2 weeks ago
31
 English (US) ·
English (US) · © Clint's Theme Park 2025. All rights are reserved
