Ollama는 새로운 멀티모달 엔진 도입을 통해, 이미지와 텍스트를 복합적으로 다루는 최신 비전 멀티모달 모델들을 지원함
Ollama의 멀티모달 모델 지원
종합 멀티모달 이해 및 추론
Llama 4 Scout
Gemma 3
문서 인식 및 분석
Qwen 2.5 VL
Ollama 멀티모달 엔진의 특징
엔진 발전의 의미
모델 모듈성
정확성 향상
메모리 관리 최적화
앞으로의 계획
감사의 글
Ollama, 멀티모달 모델을 위한 새로운 엔진 발표
 14 hours ago
1
14 hours ago
1
Related

Show GN: LLMLingua-2의 TypeScript 구현체
3 hours ago
1
생각에 대한 생각 - Thoughts on thinking
13 hours ago
0
아주 작은 Boltzmann 머신
13 hours ago
2
LLM으로 몇 달간 코딩한 후, 다시 내 두뇌를 쓰기로 했어요
13 hours ago
0
BuyMeACoffee가 조용히 여러 국가에 대한 지원을 중단함 (2024년)
13 hours ago
2
NASA가 Hail Mary식 추력기 수리로 고대 우주선 Voyager 1을 살림
13 hours ago
1
코덱스 연구 미리보기
14 hours ago
1
메이저 트라이얼에 보내는 관제 센터
14 hours ago
2
Popular
[Vibe Coding 기업 적응기] Part1: v0.dev와 함께한 3주간의 기록
4 weeks ago
62

“챗GPT도 아니고 6만쪽 어떻게 다 읽나…책임 묻겠다”…민주 초선들, 조희대 탄핵 예고
2 weeks ago
45

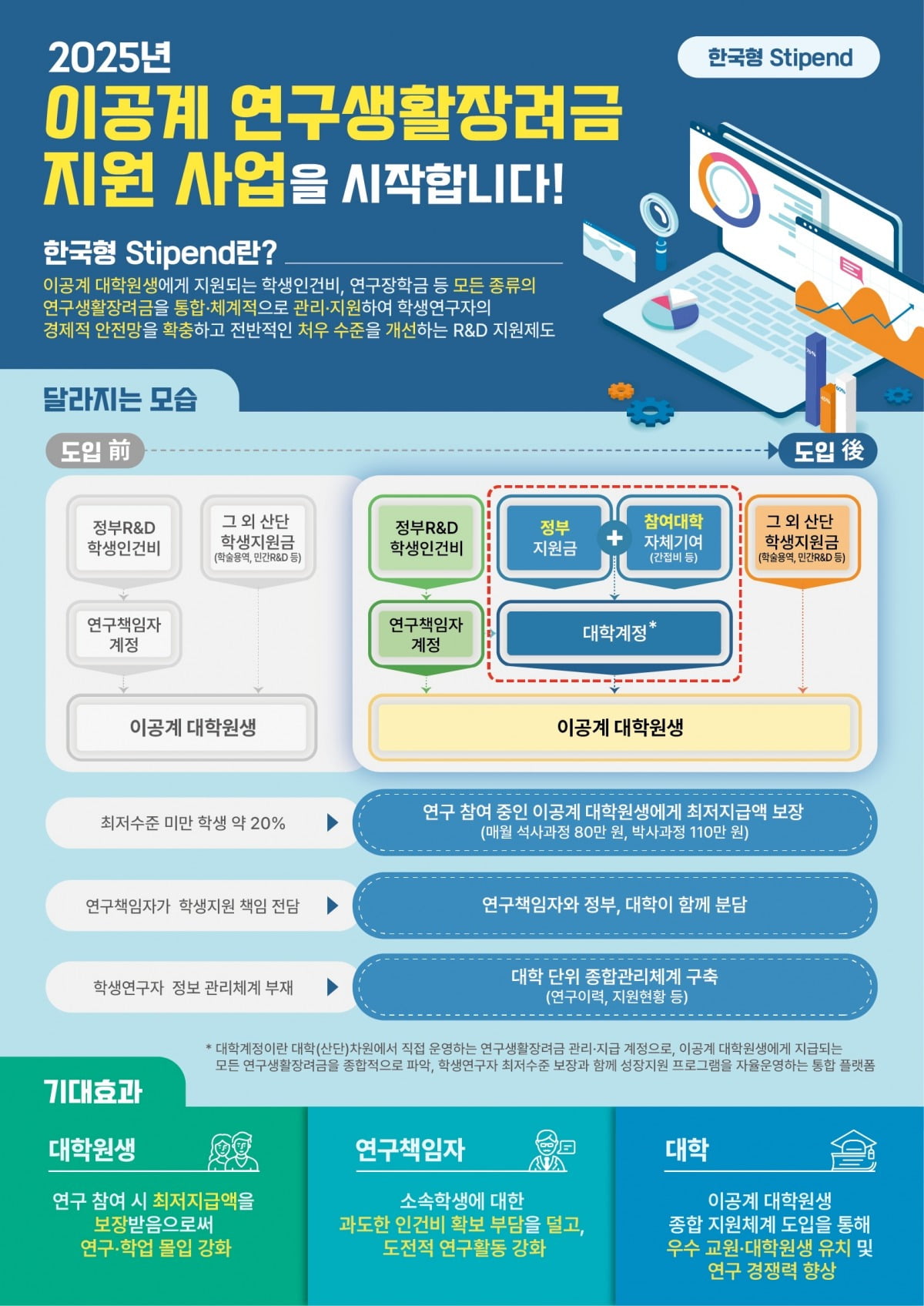
이공계 대학원생, 월 110만원 받는다…'한국형 스타이펜드' 첫걸음
3 weeks ago
44
![“뭉클했다” 친정팀 환영 영상 지켜 본 김하성의 소감 [MK현장]](https://pimg.mk.co.kr/news/cms/202504/26/news-p.v1.20250426.d92247f59a8b45a6b118c0f6ea5157ef_R.jpg)
“뭉클했다” 친정팀 환영 영상 지켜 본 김하성의 소감 [MK현장]
3 weeks ago
43


The CFO’s Guide to AI-Powered ERP | Vision33
3 weeks ago
33
Cloth 웹 시뮬레이터
2 weeks ago
33

구글 검색 반독점 재판 2차전 돌입…"크롬 매각해야" vs "中에 맞서야"
3 weeks ago
31

 English (US) ·
English (US) · © Clint's Theme Park 2025. All rights are reserved
