저장소 샘플링의 개념 및 필요성
크기를 아는 경우의 샘플링
크기를 모르는 경우의 샘플링 : 문제점 및 필요성
저장소 샘플링 알고리듬의 원리
수학적 직관 (카드 예시 활용 설명)
여러 개의 샘플 선택 확장 (k-out-of-n)
로그 수집 서비스에서의 저장소 샘플링 활용
추가 응용 및 참고 자료
결론
저장소 샘플링: 크기를 모르는 데이터에서 공정한 무작위 추출 방법
 15 hours ago
3
15 hours ago
3
Related

레일스는 기술 부채가 아니에요: 과거의 발언을 철회한 Gumroad Founder
6 hours ago
3
ChatGPT의 Deep Research, Github 코드도 분석한다.
16 hours ago
1

코드 품질 개선 기법 10편: 적절한 거리 유지에 신경 쓰자
16 hours ago
1
AI 코드 리뷰: 작성자가 리뷰어가 되어도 될까?
17 hours ago
2
새로운 사람을 뽑기 전에 창업자들이 성장을 주도하는 방법 - 션 앨리스
17 hours ago
2
빅테크 회사에서 '일을 끝냈다(Done)'는 것의 진짜 의미
17 hours ago
2
AI 부정행위, 교육을 빠르게 붕괴시키는 심각한 위협
17 hours ago
2
Mycoria - 모두가 평등하게 연결되는 오픈 네트워크
18 hours ago
2
Popular
OpenAI, GPT 4.1 공개
3 weeks ago
77
Anubis works
3 weeks ago
75
OpenAI, o3 와 o4-mini 모델 공개
3 weeks ago
56
[Vibe Coding 기업 적응기] Part1: v0.dev와 함께한 3주간의 기록
3 weeks ago
53
"100 Go Mistakes and How to Avoid Them"의 뒷이야기
3 weeks ago
48


SAP Business One Pricing & Overview
3 weeks ago
38
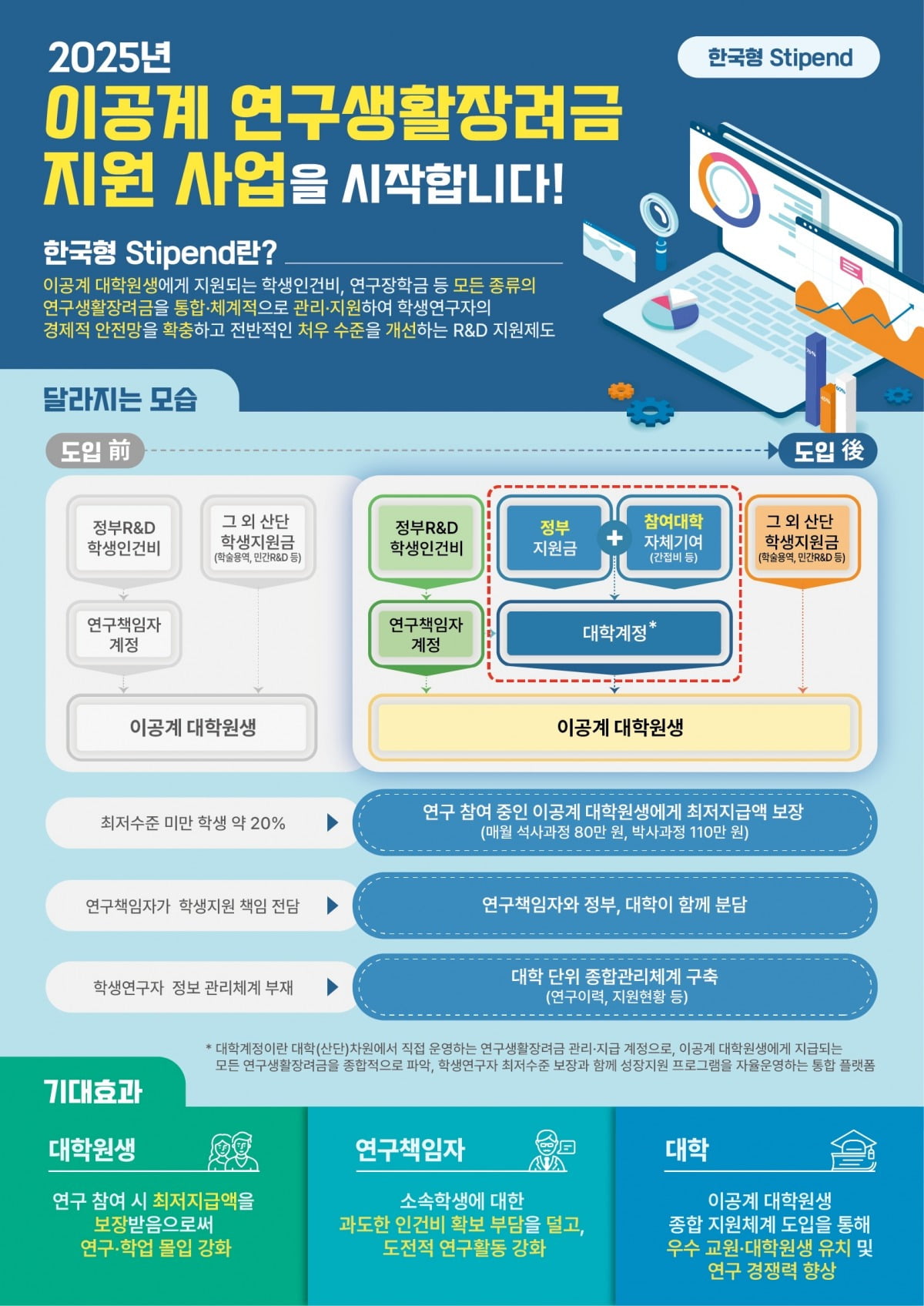
이공계 대학원생, 월 110만원 받는다…'한국형 스타이펜드' 첫걸음
2 weeks ago
35
SVG로 만드는 멋진 것들
3 weeks ago
33

 English (US) ·
English (US) · © Clint's Theme Park 2025. All rights are reserved
