마이크로서비스를 위한 Chaos Engineering
Chaos Engineering이란?
Chaos Engineering 실험 라이프사이클
Chaos Toolkit vs. Chaos Monkey
용도
설정 방식
지원 언어 및 환경
지원 장애 유형
연동 가능 시스템
사용 권장 상황
Chaos Toolkit 실습 예시 (Java/Node.js/Kubernetes)
Kubernetes 환경 실험
Istio 기반 지연 삽입
보고서 생성 및 분석
Chaos Monkey in Spring Boot
실행 방식
Chaos Engineering in Node.js
Node.js용 Chaos Monkey 활용
Chaos Toolkit 활용 예
CI/CD 파이프라인에 Chaos 통합
통합 목적
GitHub Actions 통합 예시
Chaos Engineering 실험 시 베스트 프랙티스
결론
참고 자료
마이크로서비스를 위한 Chaos 엔지니어링
 23 hours ago
2
23 hours ago
2
Related

Guider 3.9.9 릴리즈 – 10주년을 맞이한 가장 큰 업데이트!
1 hour ago
1
Flatpak의 미래
1 hour ago
1
바이낸스 최초이자 유일한 한국인 엔지니어의 수습 회고
11 hours ago
2
Readability를 대체하는 HTML-to-Markdown 오픈소스 도구 Defuddle 소개
13 hours ago
1
Show GN: MCP Bundler
14 hours ago
1
rav1d 비디오 디코더 성능 개선
15 hours ago
0
유발 하라리가 말하는 사람들이 진실에 관심이 없는 이유
20 hours ago
0

문의 대응을 효율화하기 위한 RAG 기반 봇 도입하기
21 hours ago
1
Popular

김문수, 배현진에 “미스 가락시장” 발언 놓고 논란
1 week ago
82
Gmail to SQLite
1 week ago
71
21 GB/s 속도의 AMD 9950X에서 SIMD를 활용한 CSV 파싱
1 week ago
68

“챗GPT도 아니고 6만쪽 어떻게 다 읽나…책임 묻겠다”…민주 초선들, 조희대 탄핵 예고
2 weeks ago
47
![“뭉클했다” 친정팀 환영 영상 지켜 본 김하성의 소감 [MK현장]](https://pimg.mk.co.kr/news/cms/202504/26/news-p.v1.20250426.d92247f59a8b45a6b118c0f6ea5157ef_R.jpg)
“뭉클했다” 친정팀 환영 영상 지켜 본 김하성의 소감 [MK현장]
3 weeks ago
46
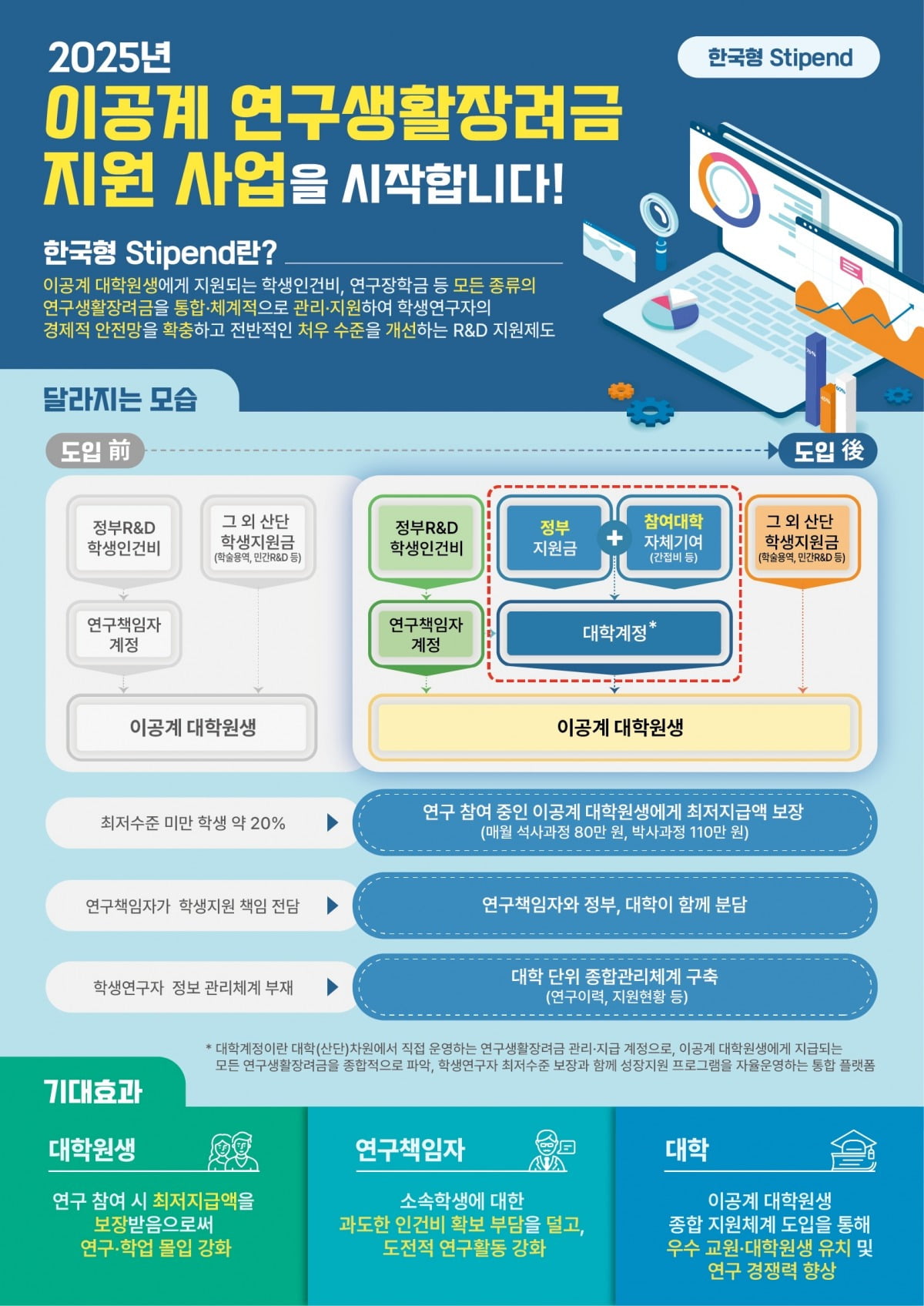
이공계 대학원생, 월 110만원 받는다…'한국형 스타이펜드' 첫걸음
4 weeks ago
46
Cloth 웹 시뮬레이터
3 weeks ago
41

Maintaining Security Material with SAP Cloud Integration
3 weeks ago
33


교황 선출 비밀투표를 OTT로…판돈 260억 몰린 '콘클라베' 생중계
2 weeks ago
31
 English (US) ·
English (US) · © Clint's Theme Park 2025. All rights are reserved
