안녕하세요. Matching Dev Team의 Milo입니다.
Azar는 전 세계 유저들을 24/7 연결하고 있으며, 즐거운 연결 경험을 제공하기 위해 세션 기반 추천 시스템1을 운영하고 있습니다. 이 추천 시스템은 유저의 행동이나 선호도 같은 정보를 바탕으로 맞춤형 추천을 제공하는 방식입니다. 추천 품질을 높이려면 유저의 최신 정보를 실시간 반영하는 것이 중요합니다. 유저의 최신 정보는 서로 다른 시점에 실시간으로 생성된 여러 이벤트로 존재했고, 파편화된 이벤트를 조합하여 추천에 활용할 수 있는 데이터로 변환하는 것이 필요했습니다. 뒤에 설명드리겠지만, 실시간으로 여러 이벤트를 조합하는 규칙이 단순하지 않았기 때문에 새로운 스트림 조인 서비스를 구축하게 되었습니다.
이번 포스트에서는 Azar의 AI 기반 실시간 매칭 시스템을 위해 유저의 이벤트를 어떻게 실시간으로 조합하고, 결과를 안정적으로 제공할 수 있었던 경험을 소개합니다.
기능 요구사항
- 다른 시점에 발생하는 유저 이벤트를 조합할 수 있어야 합니다.
- 유저 이벤트가 일부 유실되더라도 정의된 조건에 따라 조합할 수 있어야 합니다.
- 유저 이벤트는 다양한 조합이 가능해야 합니다.
- 예시: 매치 요청 → 대화 완료 (성공적인 매칭)
- 예시: 매치 요청 → 요청 취소 (매칭 취소)
비기능 요구사항
- 이벤트 조합과 결과 생성을 최소한의 지연으로 처리해야 합니다.
- 조합된 데이터는 유실 없이 정확히 한 번(Exactly Once)만 제공되어야 합니다.
- 시스템 배포나 업데이트 시에도 서비스 중단 없이(Zero downtime) 지속적으로 데이터를 제공해야 합니다.
아래 그림과 같은 실시간 스트림 조인 파이프라인을 구성하고자 했습니다.
 그림 1. 실시간 스트림 조인 파이프라인 구성
그림 1. 실시간 스트림 조인 파이프라인 구성
실시간 이벤트 조합을 위한 스트리밍 플랫폼 선정
실시간 이벤트 조합을 위한 스트리밍 플랫폼을 선정하기 위해 여러 기술을 분석했습니다. 실시간성과 복잡한 이벤트 조합이 요구되므로, 다음과 같은 기술 스택을 고려했습니다.
| Spark Streaming | 배치/스트림 통합, 풍부한 Spark API 생태계 |
마이크로배치 기반으로 인한 지연 | ❌ 밀리초 단위 지연이 중요한 실시간 처리에 부적합 |
| Kafka Streams | 간단한 API, Kafka와 자연스러운 통합 |
복잡한 시간 처리에 제한적 (Schedule 기반 시간만 지원) |
❌ Event Time 기반 타임아웃 등 정밀 제어의 한계 |
| Apache Flink | 낮은 지연, 정밀한 시간 처리 지원 |
높은 학습 곡선, 초기 진입 장벽 |
✅ 실시간 처리 요구사항(상태, 시간, 지연 제어 등)에 가장 적합 |
조금 더 자세한 Apache Flink의 특징은 다음과 같습니다.
- 낮은 지연: Flink는 Record-by-Record 단위의 데이터 처리 방식을 기반으로 하여, 데이터를 받는 즉시 연산을 수행합니다. 배치처럼 데이터를 모아서 처리하지 않고, 흐름 속에서 연산이 일어나므로 밀리초 단위의 지연으로도 실시간 처리가 가능합니다.
- 상태 관리: Flink는 애플리케이션 수준에서 상태를 안전하게 저장하고 관리할 수 있도록 내장된 상태 백엔드(예: RocksDB)를 제공합니다. 이를 통해 이벤트 누적, 집계, 중복 제거, 타임아웃 처리 등 복잡한 상태 기반 로직을 안정적으로 구현할 수 있습니다. 또한, Exactly-once 처리 보장 및 장애 복구도 지원됩니다.
- 시간 관리: Flink는 Processing Time, Event Time, Ingestion Time을 모두 지원하며, 특히 Event Time을 기반으로 한 시간 제어가 강력한 특징입니다. Watermark를 통해 out-of-order 이벤트도 올바르게 처리할 수 있고, 시간 기반 윈도우 연산을 수행할 수 있습니다.
실시간 이벤트 조합 처리로 Kafka Streams와 Apache Flink 둘 다 서비스를 구성하기 위한 좋은 선택이었지만, Flink의 정밀한 시간 제어 기능이 Azar의 복잡한 요구사항을 충족하는 데 더 적합하다고 판단했습니다.
하지만 Flink를 선택한 것만으로 모든 문제가 해결된 것은 아니었습니다. 바로 Flink가 제공하는 강력한 Window API를 사용할 것인가, 아니면 더 깊은 수준의 제어가 가능한 로우 레벨(low-level) API를 사용할 것인가 하는 문제였습니다.
복잡한 요구사항을 만족하는 스트림 조인 처리
(Flink Window 방식의 한계와 KeyedProcessFunction 선택 배경)
앞서 정의한 요구사항을 충족하기 위한 스트림 조인 처리 방식으로 Flink의 Window API(Tumbling, Sliding, Session, Global Window)를 고려했습니다. Window API는 시간 기반으로 이벤트를 그룹화하고, 집계 및 조인 연산을 수행할 수 있는 기능을 제공합니다. 조금 더 복잡한 설정을 하자면 Trigger, Evictor, ProcessFunction 등을 통해 윈도우 내 이벤트를 제어할 수 있습니다.
그럼에도 Window API는 정형화된 시간 기반 처리로, 불특정한 시점에 도착할 이벤트의 경우를 기다리기 어렵습니다. 보다 세밀한 시간 제어가 가능한 도구를 찾게 되었고 Flink의 KeyedProcessFunction2을 선택하게 되었습니다.
KeyedProcessFunction은 다음과 같은 이점을 제공합니다.
- Key 기반3 이벤트 처리: KeyedProcessFunction은 이벤트를 키별로 분리하여 처리할 수 있어, 각 키에 대한 상태를 독립적으로 관리할 수 있습니다.
- 상태 관리의 유연성: Value, List, Map, Reducing, Aggregating State를 지원하며, 각 키에 대한 상태를 독립적으로 관리할 수 있습니다.
- TimerService를 통한 시간 제어: TimerService를 사용하여 이벤트 도착 시점 또는 유형에 따라 타이머를 설정하고, 타이머가 만료되었을 때 비동기적으로 onTimer를 호출합니다.
특히 세밀한 시간 제어가 가능했던 이유는 KeyedProcessFunction에서만 사용 가능한 TimerService4가 있기 때문입니다.
- 처리 시간 또는 이벤트 시간 기반으로 타이머를 설정할 수 있습니다.
- 타이머 크기를 일관되지 않고 유연하게 설정할 수 있습니다.
- 타이머를 연장하거나 취소할 수 있는 기능을 제공합니다.
이러한 기능을 통해 Azar의 실시간 이벤트 조합 요구사항을 충족할 수 있는 유연한 스트림 조인 처리를 구현할 수 있었습니다.
KeyedProcessFunction을 활용하여 실제 스트림 조인을 구현할 때는 State를 통한 이벤트 상태 관리와 TimerService를 통한 정교한 시간 제어가 핵심입니다. 다음은 Azar의 실시간 이벤트 조합 요구사항을 충족하기 위한 구체적인 구현 방법입니다.
KeyedProcessFunction에서 이벤트 조합 로직 구현
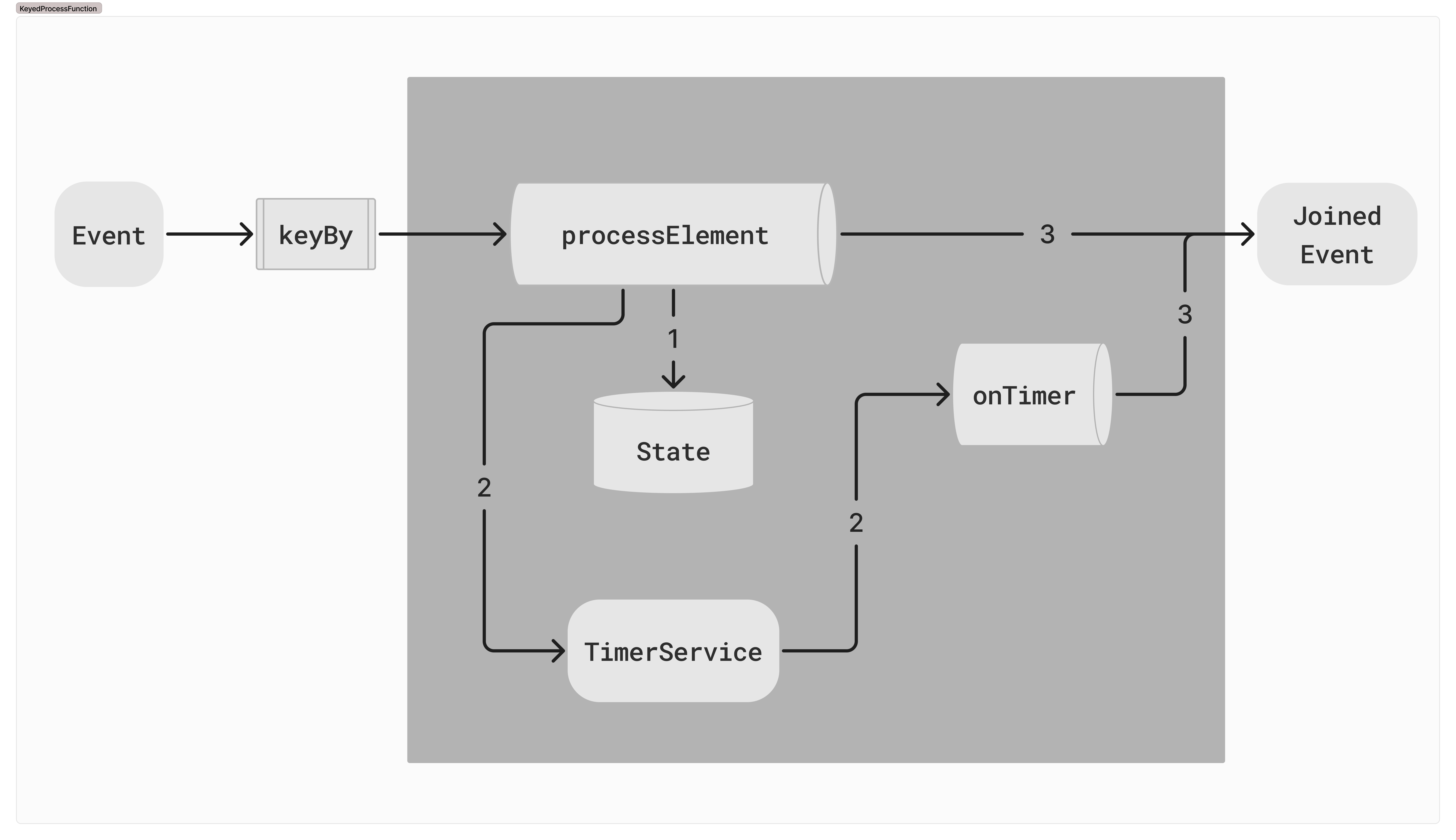 그림 2. KeyedProcessFunction을 이용한 이벤트 조합 로직
그림 2. KeyedProcessFunction을 이용한 이벤트 조합 로직
- 이벤트 수집 및 상태 관리
- 각 이벤트는 고유 식별자(예: 유저 ID, 이벤트 타입 등) 키를 기준으로 파티셔닝되어 KeyedProcessFunction의 각 인스턴스로 분산됩니다.
- 각 키마다 상태를 유지하여 이벤트 도착할 때마다 상태를 업데이트합니다.
- 타이머 설정 및 관리
- 이벤트가 도착할 때마다 TimerService를 사용하여 타이머를 설정합니다.
- 타이머는 이벤트의 종류나 도착 순서에 따라 유연하게 대기 시간을 조절합니다.
- 타이머가 만료되면 KeyedProcessFunction의 onTimer 메서드를 호출하고, 조합 로직을 실행합니다.
- 타이머 연장
- 유저의 활동이 발생하면 기존 타이머를 제거하고 새로운 타이머를 등록하여 지연 시간을 연장합니다.
- 이렇게 함으로써 유저의 활동을 지속적으로 감지하고, 필요한 이벤트를 기다릴 수 있습니다.
- 조합 로직(Join) 실행
- 이벤트가 도착했거나 타이머가 만료되면, 현재 상태를 기반으로 이벤트 조합 로직을 실행합니다.
- 조합 결과는 다음과 같은 조건에 따라 결정됩니다.
- 전체 발행: 모든 필수 이벤트가 도착한 경우, 조합 결과를 즉시 발행합니다.
- 부분 발행: 일부 필수 이벤트가 도착했지만, 추가 이벤트를 기다리는 경우 타이머 만료 시 조합 결과를 발행합니다.
- 발행하지 않음 (누락 처리): 필수 이벤트가 도착하지 않은 경우, 조합 결과를 발행하지 않습니다.
자세한 구현은 하단의 부록을 참고해주세요.
구현된 KeyedProcessFunction은 어떻게 동작할까요?
 그림 3. 도착/누락 시나리오별 KeyedProcessFunction의 조합 결과 예시
그림 3. 도착/누락 시나리오별 KeyedProcessFunction의 조합 결과 예시
3가지 가정을 바탕으로 KeyedProcessFunction을 이용한 이벤트 조합 예시를 설명하겠습니다.
- 그림과 같이 A, B, C의 이벤트를 소비하며, 1초마다 발행된 이벤트라 가정하겠습니다.
- 총 3개의 이벤트(1번, 2번, 3번)가 조합되어야 하며, 2번 이벤트가 필수 이벤트라고 가정하겠습니다.
- 최대 3초의 지연 시간을 설정하고, 이벤트가 도착하지 않으면 타이머가 만료되어 조합 로직을 실행합니다.
그림의 결과를 설명하자면 다음과 같습니다.
- A 이벤트는 A1, A2가 있고 A3를 기다리는 타이머가 만료되어 onTimer에서 조합 로직을 실행합니다. 필수 이벤트로 A2를 포함하기 때문에 부분 발행 합니다.
- B 이벤트는 B1, B2, B3가 있고 B3가 도착해서 processElement에서 조합 로직을 실행합니다. 전체 이벤트를 포함하기 때문에 즉시 전체 발행 합니다.
- C 이벤트는 C1이 있고 C2, C3 이벤트를 기다리는 타이머가 만료되어 onTimer에서 조합로직을 실행합니다. 필수 이벤트 C2의 부재로 발행하지 않고 누락 처리 합니다.
TimerService를 활용한 지연 시간 관리
실시간 이벤트 조합에서 지연 시간은 매우 중요한 요소입니다. 너무 긴 지연 시간은 실시간성을 떨어뜨리고, 너무 짧은 지연 시간은 필요한 이벤트를 누락시킬 수 있습니다. Flink의 KeyedProcessFunction에서 TimerService를 활용하여 적절한 지연 시간 설정하는 방법을 소개합니다.
최소한의 지연 시간 설정으로 실시간성 보장
다른 시점에 발생한 이벤트를 최대한 짧은 지연 시간을 유지하면서도 필요한 이벤트를 모두 포함시킬 수 있는 적절한 지연 시간을 설정하는 것이 필요했습니다. 제가 조합해야 할 이벤트의 event timestamp를 분석해보니 이벤트마다 다른 크기의 지연 시간이 필요했습니다. TimerService를 사용하면 기존에 설정된 타이머를 제거하고 새로운 타이머를 등록할 수 있어, 이벤트에 따라 유연하게 지연 시간을 조정할 수 있었습니다.
이렇게 최소한의 지연 시간을 설정하여 불필요하게 기다리는 시간을 제거할 수 있었고, 실시간성을 높일 수 있었습니다.
지연 시간 연장으로 조합 성공률 향상
최소한의 지연 시간 설정으로 불필요하게 기다리는 시간을 제거할 수 있었지만, 필요한 유저의 이벤트가 타이머 기간 동안 발생하지 않는 경우도 있었습니다. 이 경우, 타이머가 만료되어 조합이 실패할 수 있습니다. 이런 문제를 개선하기 위해선 지속적으로 타이머를 연장하는 로직이 필요했습니다. 필요한 유저의 이벤트를 기다리기 위해 heartbeat 이벤트를 도입했습니다.
heartbeat 이벤트로 유저가 유효한 활동을 하고 있는지 감지하면서 조금씩 타이머를 연장하는 방식으로 필요했던 유저 이벤트를 기다렸다가 조합 성공률을 높일 수 있었습니다.
실시간 유저 이벤트를 조합하는 비즈니스 로직을 구현했지만, AI 추천 시스템은 실시간 반영이 중요하기 때문에 배포 중 발생하는 잠깐의 서비스 중단도 유저 경험과 서비스 품질에 영향을 줄 수 있습니다.
AI 추천 시스템에게 실시간 전달을 보장하기 위해선 아래 2가지 문제를 해결해야 합니다.
- 애플리케이션을 배포할 때 상태(State)를 안전하게 저장하고 복구해야 합니다.
- 애플리케이션을 배포할 때 서비스 중단 없이(Zero downtime) 배포해야 합니다.
Flink는 애플리케이션 수준에서 상태를 관리하기 때문에 Stateful 합니다. 그래서 단순히 Flink 애플리케이션을 배포하는 것만으론 상태를 안전하게 저장하고 복구할 수 없습니다. 상태 유실 없이 안전하게 저장하고 복구할 수 있는 방법이 필요했고, 이를 위해 Flink에서 제공하는 Savepoint를 사용했습니다.
Savepoint로 상태를 복구
Flink Savepoint는 Trigger된 특정 시점의 State Snapshot으로, Flink 애플리케이션의 State를 저장하고 복구하는 데 사용됩니다. 여기서 State Snapshot에는 Kafka Commit Offset, 타이머 그리고 Flink Operator5에서 정의한 State가 포함됩니다.
Savepoint를 통해 애플리케이션의 상태를 안전하게 저장하고, 새로운 버전의 애플리케이션은 이전 상태로부터 시작할 수 있도록 합니다.
타이머를 가진 Savepoint 복구 시 고려사항
Savepoint로 복구하도록 설정했고 유실 문제를 해결했지만, 복구 시점에 이벤트 조합 성공률이 낮아지는 것을 확인했습니다. 이유는 Savepoint가 생성된 이후 복구 시점 사이에 만료될 타이머가 존재하기 때문입니다. 타이머들은 애플리케이션이 복구 완료됨과 동시에 KeyedProcessFunction의 onTimer를 호출하게 됩니다.
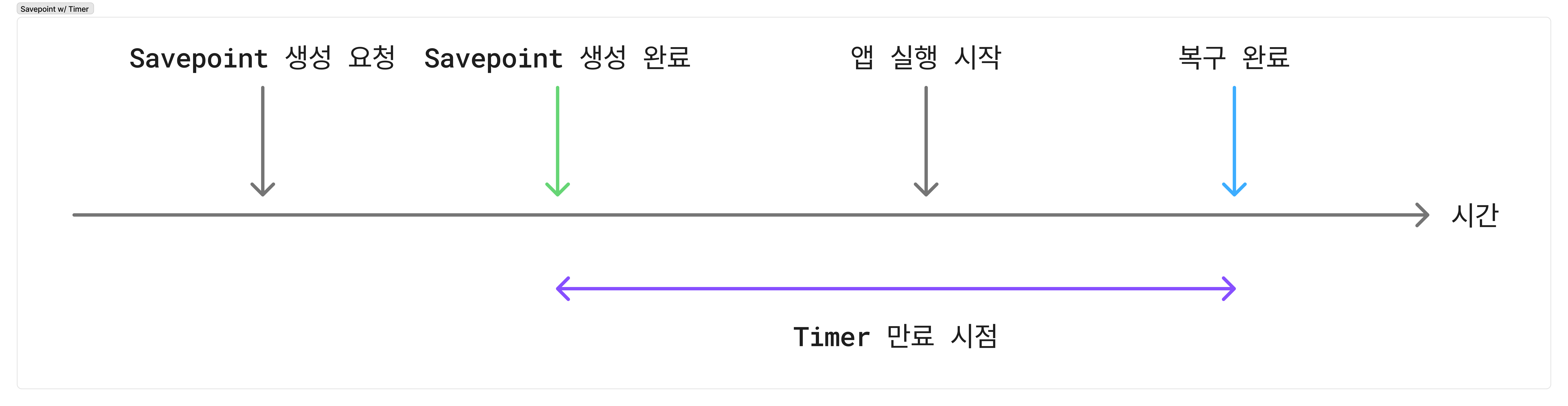 그림 4. Savepoint 생성 후 복구 완료 시점까지의 만료된 타이머
그림 4. Savepoint 생성 후 복구 완료 시점까지의 만료된 타이머
복구된 시점에 이미 만료된 타이머는 onTimer 호출 시, 배포 시점 이전에 설정된 타이머라면 기간을 연장해 조금 더 기다렸다가 조합될 수 있도록 합니다. 구체적인 방법은 다음과 같습니다.
- 연장시키고 싶은 상태를 가진 Operator에 CheckpointedFunction을 상속하고 initializeState, snapshotState를 override합니다.
- initializeState은 상태 초기화를 할 때 한 번 호출되는데, 해당 시점의 timestamp를 저장합니다.
- 복구가 완료되고 onTimer가 호출되면, initializeState에서 저장된 timestamp를 기준으로 타이머를 연장합니다.
위 작업을 한 결과, 일시적으로 떨어지던 이벤트 조합 성공률을 배포 직후에도 유지할 수 있었습니다.
무중단 서비스 배포
Savepoint를 통해 상태를 유실 없이 안전하게 복구할 수 있게 되었습니다. 이제 실시간 전달을 보장하기 위해, 중단 없는 배포 방법을 찾아야 했습니다. 기본적으로 Flink는 무중단 서비스 배포 지원이 없어 직접 구성해야 했고, 제가 찾은 것은 Blue-Green 배포 전략6이었습니다.
Blue-Green 배포 전략
Blue-Green 배포 전략은 두 개의 독립적인 환경(Blue와 Green)을 운영하여, 새로운 버전의 서비스를 배포할 때 기존 서비스에 영향을 주지 않고 안정적으로 전환할 수 있는 방법입니다. 이 전략을 통해 다음과 같은 이점을 얻을 수 있었습니다.
- 무중단 배포: 새로운 버전의 서비스가 준비되면 기존 서비스에 영향을 주지 않고 트래픽을 전환할 수 있습니다.
- 신속한 롤백: 새로운 버전에서 문제가 발생할 경우, 트래픽을 기존 버전으로 쉽게 되돌릴 수 있어 안정성을 높입니다.
Flink는 기본적으로 Blue-Green 배포 전략을 지원하지 않아 별도 구성해야 했고, 정리한 배포 과정은 아래 상세 배포 과정의 그림을 참고해주시면 됩니다.
상세 배포 과정
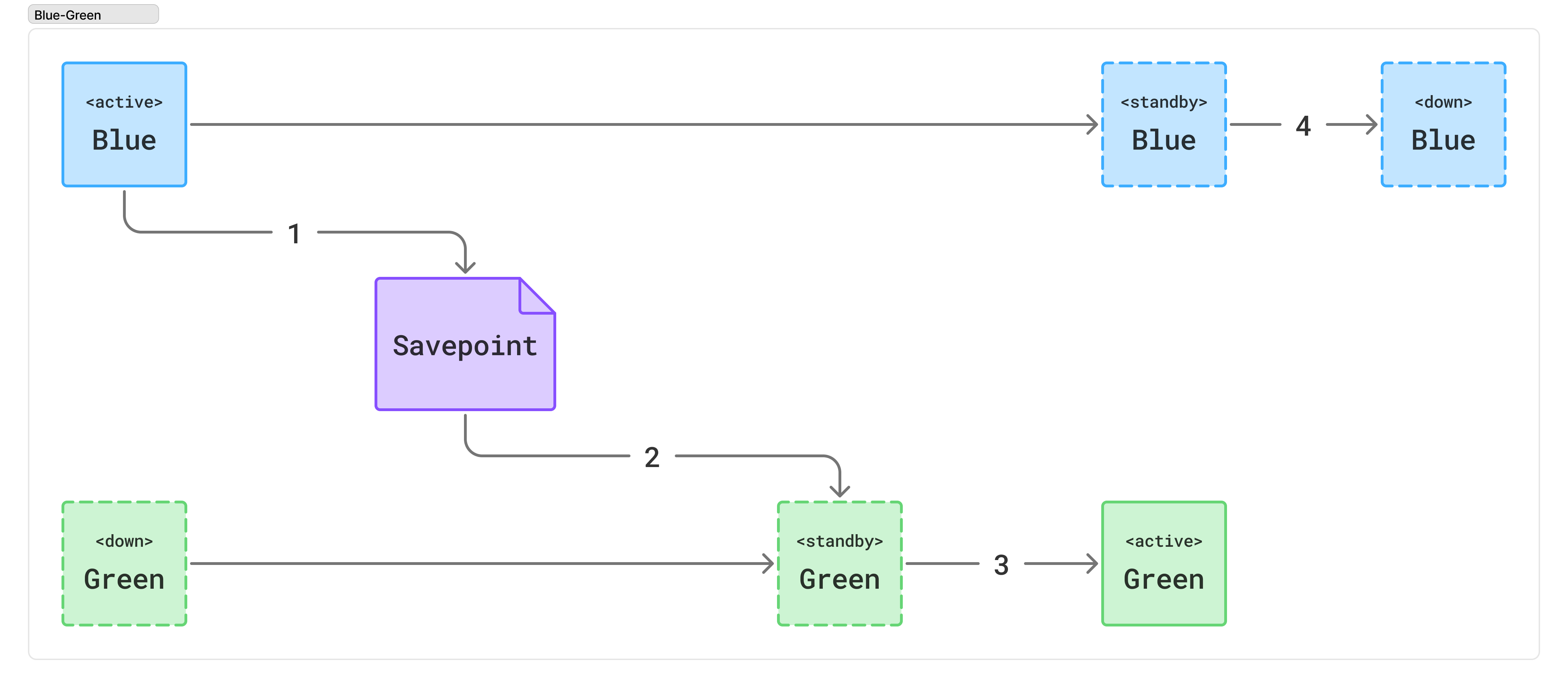 그림 5. Blue-Green 배포 과정
그림 5. Blue-Green 배포 과정
- Savepoint 생성
- 기존 서비스의 상태와 Kafka 오프셋을 Flink의 Savepoint를 통해 정확히 저장합니다.
- 상태 복구 및 신규 서비스 배포
- 새로운 서비스가 저장된 Savepoint로부터 상태를 복원해 실행합니다.
- Consumer Lag 해소
- 신규 서비스가 완전히 동기화되면, 트래픽을 전환할 준비를 합니다.
- 전환 및 종료
- 신규 서비스가 정상적으로 가동되면 기존 서비스는 종료합니다.
이 과정을 수동으로 진행하는 경우 휴먼 에러가 발생하거나 Savepoint를 생성한 이후 배포가 늦어질수록 Consumer Lag이 커지는 문제가 있었습니다. Spinnaker Pipeline을 통해 자동화하여 배포를 진행했기 때문에, Savepoint 생성 이후 신규 서비스 배포까지의 시간을 최소화할 수 있었습니다.
실시간 이벤트 조합과 무중단 배포를 성공적으로 구현하며, 저희의 스트림 조인 서비스는 Azar의 AI 추천 시스템에 신선하고 신뢰도 높은 데이터를 실시간으로 공급하는 핵심 엔진이 되었습니다. 서비스가 안정적으로 운영되면서, 이 고품질 조합 데이터의 가치를 알아본 다른 서비스들이 점차 늘어나기 시작했습니다.
자연스럽게 저희의 데이터는 AI 추천 시스템을 넘어, 사내의 다양한 서비스와 모니터링 시스템에서 참조하는 단일 진실 공급원(Single Source of Truth, SSOT) 으로 자리매김하게 되었습니다. 이렇게 되자 데이터의 정합성을 보장해야 하는 더 큰 책임이 따랐습니다. 만약 조합된 이벤트가 중복으로 전달된다면, 이를 소비하는 모든 서비스에서 각자 중복 제거 로직을 구현해야 하는 비효율이 발생합니다. 더 나아가, 시스템 간 데이터 불일치를 유발하여 서비스 전체의 신뢰도를 떨어뜨릴 수 있는 위험도 있었습니다.
이러한 배경에서 Producer인 저희 스트림 조인 서비스가 정확히 한 번(Exactly-Once)만 데이터를 전달하는 것을 보장하는 것은 선택이 아닌 필수 과제가 되었습니다.
Exactly Once Semantics란?
Exactly Once Semantics(정확히 한 번의 의미)는 데이터 스트림 처리 시스템에서 각 이벤트가 정확히 한 번만 처리되고 전달되는 것을 보장하는 개념입니다. 이는 데이터 중복이나 유실 없이 신뢰할 수 있는 데이터 처리를 가능하게 합니다.
Producer에서 정확히 한 번 전달을 보장한다는 것은, 이미 한 번 발행된 이력이 있는 동등한 데이터가 중복으로 발행되지 않도록 하는 것을 의미합니다. 예를 들어, 유저 A가 1번 이벤트를 발생시킨 후, Producer가 이 이벤트를 Kafka에 발행했다면, Producer는 유저 A의 1번 이벤트를 다시 발행하지 않아야 합니다.
유실이 발생할 수 있는 문제는 앞서 해결했기 때문에, 중복 문제만 해결하면 정확히 한 번을 만족시킬 수 있었습니다. 중복이 발생할 수 있는 경우를 정리해보니 다음과 같았습니다.
- Kafka 장애로 인해 재소비가 발생할 때
- Blue-Green 배포 시 독립된 2개의 서비스가 동시에 Kafka에 메시지를 발행하는 경우
- Flink 애플리케이션이 Restart할 때 Latest Checkpoint를 기준으로 재소비하는 경우
위 3가지 경우를 확인했고, 중복을 제거(Deduplication)하기 위한 방법을 고민했습니다.
적합하지 않았던 방법들
Kafka Sink의 Exactly Once Semantics 활성화
Kafka Sink의 Exactly Once Semantics7을 활성화하는 방법은 Flink의 기본 설정을 통해 간단하게 적용할 수 있습니다. 그러나 이 방법은 2 Phase Commit(2PC) 매커니즘을 사용하기 때문에 Checkpoint 주기마다 메시지를 발행하게 되어, 실시간성이 크게 저하되는 문제가 있었습니다. Azar의 AI 추천 시스템은 높은 실시간성을 요구했기에 이 방법은 적합하지 않았습니다.
State를 가진 Operator를 별도로 구성
이전에 발행한 값을 State로 관리하는 Operator를 구성하여 중복 제거하는 방법도 고려했지만, Blue-Green 배포 전략에서는 독립된 두 서비스 간 중복 발행 여부를 판단할 수 없었습니다.
적합했지만 개선이 필요한 방법
중복 제거 Flink 애플리케이션 별도 구성
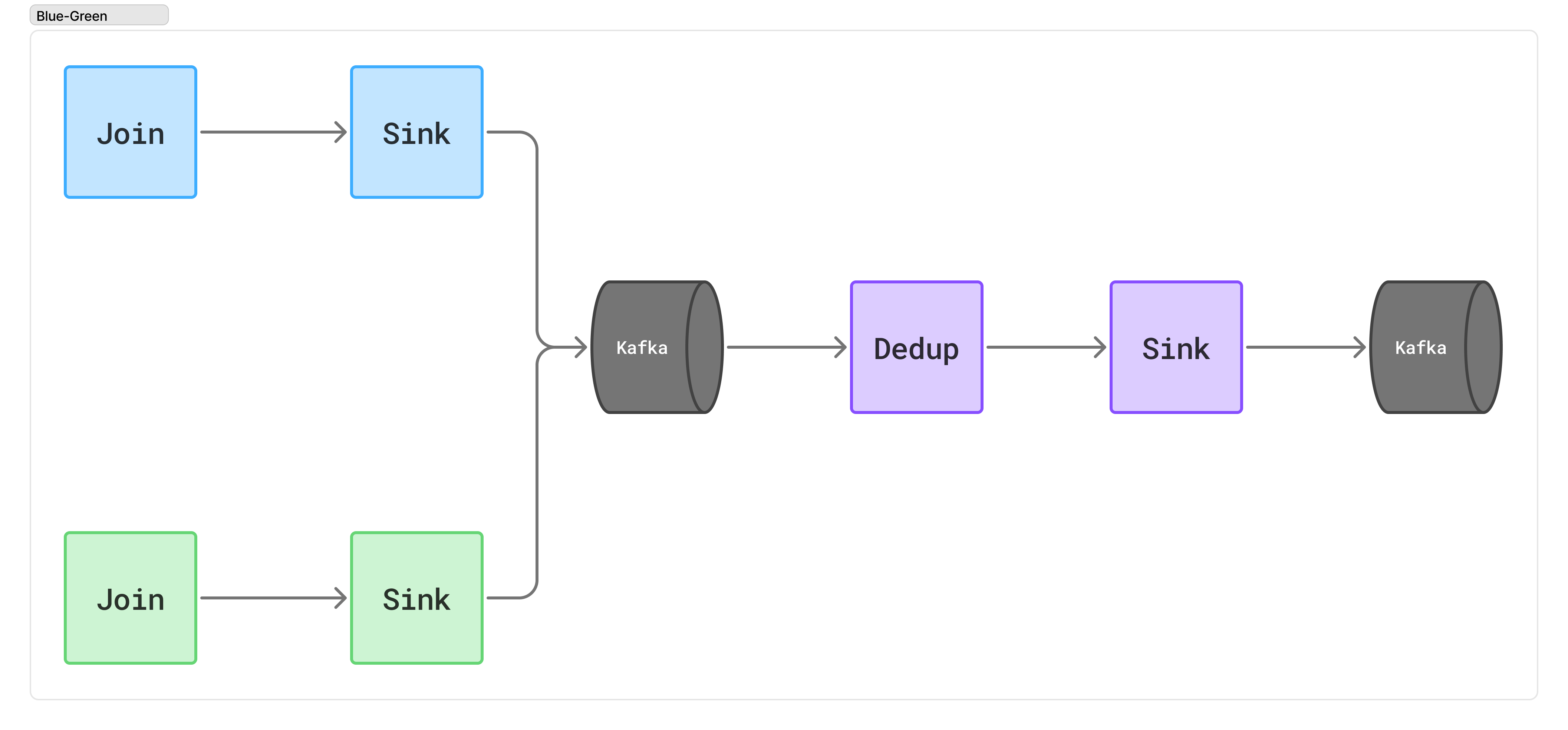 그림 6. 중복 제거(Deduplication, Dedup) Flink 애플리케이션 별도 구성
그림 6. 중복 제거(Deduplication, Dedup) Flink 애플리케이션 별도 구성
이 방법은 Flink 애플리케이션을 별도로 구성하여 중복 제거 로직을 구현하는 방식입니다. 중복 여부를 판단하기 위해 Flink의 상태를 활용해서 발행 여부를 저장합니다. 다만 Checkpoint, Savepoint 그리고 중복 처리가 되지 않은 Kafka Topic과 중복 처리된 Kafka Topic 같이 추가적인 리소스 사용과 운영 비용이 발생합니다.
최종 선택: Redis를 활용한 중복 제거 로직
Redis를 활용한 중복 제거 로직은 Redis의 빠른 메모리 기반 연산을 이용하여 중복 여부를 신속하게 판단할 수 있는 방법입니다. 이 방법은 Redis의 SET NX 명령어 또는 Lua script를 사용하여 독립된 2개의 서비스에서도 동시성 문제 없이 중복 여부를 판단할 수 있습니다. Redis는 빠른 응답 속도를 제공하므로, 이벤트 처리 지연 시간을 최소화할 수 있습니다.
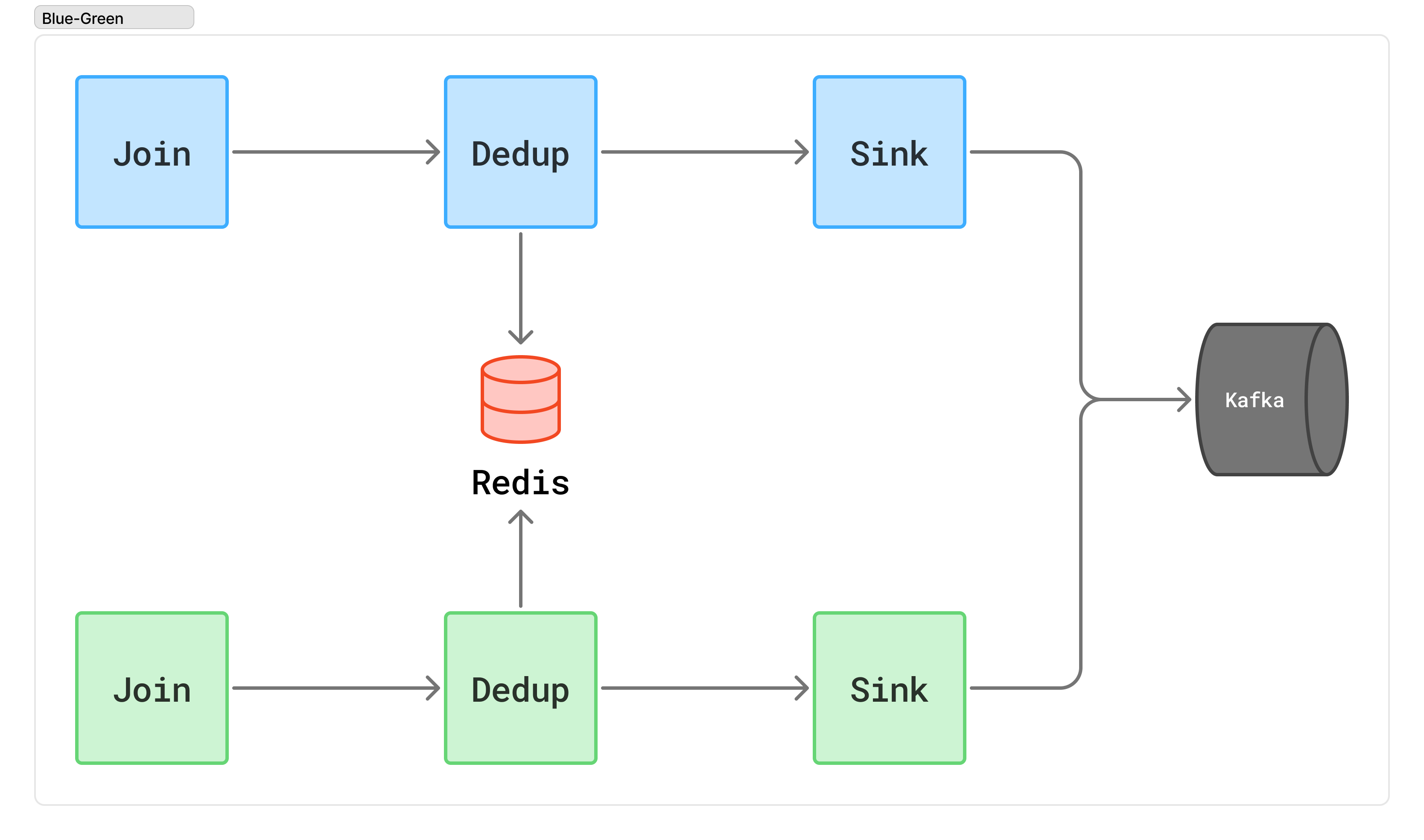 그림 7. Redis의 Atomic 연산을 활용한 중복 제거(Exactly Once) 파이프라인
그림 7. Redis의 Atomic 연산을 활용한 중복 제거(Exactly Once) 파이프라인
앞서 설명드렸던 중복 제거 Flink 애플리케이션을 별도 구성해서 사용했지만, 최근 Redis로 대체하면서 중복 제거까지의 지연 시간을 평균 300ms -> 3ms 미만으로 크게 개선할 수 있었습니다.
실시간 이벤트 조합과 무중단 배포를 통해 Azar의 AI 추천 시스템은 유저에게 더욱 신뢰할 수 있는 추천 서비스를 제공할 수 있게 되었습니다. AI 추천 시스템 뿐만 아니라 다른 서비스나 모니터링에도 실시간 조합 데이터를 활용하게 되었으며 나아가 사내 데이터 분석의 원천 데이터로 활용될 예정입니다.
이번 실시간 스트림 조인 서비스를 구현하며 Flink의 상태 관리와 타이머 제어에 대한 깊은 이해를 얻을 수 있었습니다. 향후에는 현재의 스트림 조인 서비스를 기반으로 더 많은 동료들이 쉽게 데이터에 접근하고 활용할 수 있는 데이터 플랫폼으로 발전시키는 것을 목표로 하고 있습니다.
감사합니다!
KeyedProcessFunction 구현 예시입니다. 이 코드는 이벤트를 조합하고, 타이머를 설정하며, 상태를 관리하는 로직을 포함하고 있습니다.










![[속보]李대통령, G7 참석차 내일 출국…“주요국 정상과 양자회담 조율”](https://dimg.donga.com/wps/NEWS/IMAGE/2025/06/15/131807427.2.jpg)


 English (US) ·
English (US) · 