Introduction
In Part 1 of this blog series, we explored how customers using SAP Content Server could leverage Amazon S3 as the document store to create a cost-effective, robust, scalable solution for document management. In this second part of our blog series, we will share how customers can increase the reliability of SAP Content Server on Amazon S3 by implementing High Availability (HA).
Why is High Availability in SAP Content Server crucial?
According to Uptime Institute’s “2025 Annual Outage Analysis Report”, whilst 54% of organizations report their most recent significant outage cost over $100,000, 20% experienced costs exceeding $1 million per incident. This disruption cascades through the organization, affecting order processing, customer service operations, and compliance requirements. For organizations running mission-critical SAP workloads, the SAP Content Server forms the backbone of document management operations.
When business processes rely on immediate access to purchase orders, invoices, contracts, and regulatory documentation, any disruption to the SAP Content Server can impact business operations. Therefore, it is very important for SAP Content Server to be configured with High Availability, so it remains operational and accessible despite potential hardware, software or network failures.
Proposed Architecture
In Part 1 of this blog series, we covered setting up Amazon S3 File Gateway as the file system for content stored in SAP Content Server. We created a content repository and configured SAP ERP to access the content repository. Additionally, we provided a step-by-step guide for migrating content from SAP MaxDB to Amazon S3.
The S3 File Gateway service has an availability SLA of 99.9%, which translates to a monthly unplanned downtime of at most 43 minutes. This proposed HA solution is only necessary if your organisation requires this availability SLA. Three different scenarios where this HA solution can be used are shown in Figures 1, 2 and 3, below.
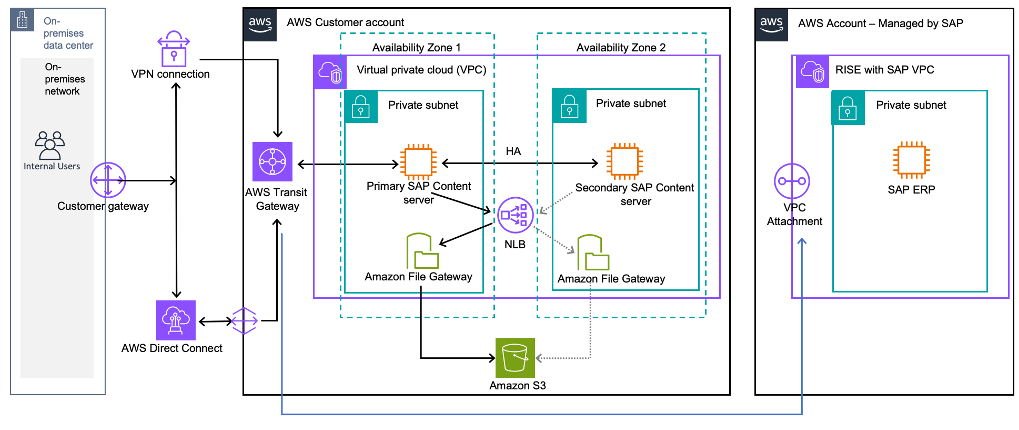
Figure 1: SAP Content Server with High-Availability connected to RISE with SAP on AWS
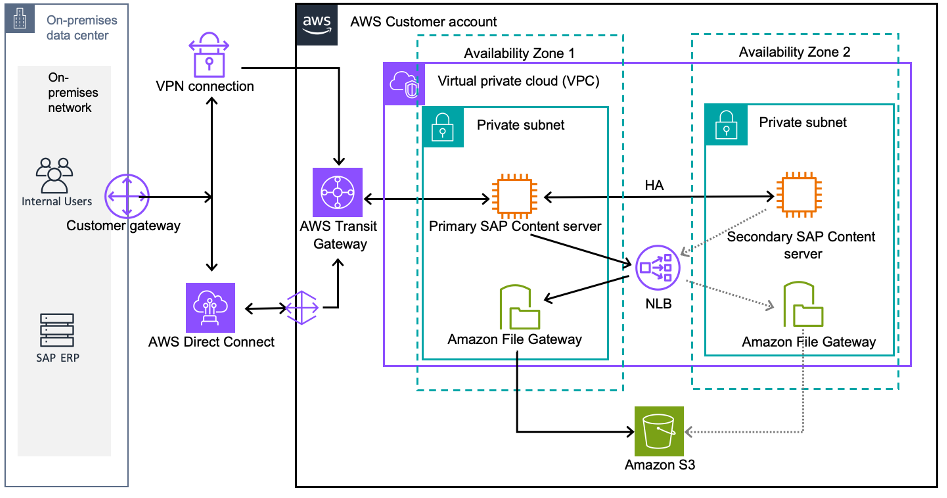
Figure 2: SAP Content Server with High-Availability on AWS connected to on-premises SAP ERP Servers
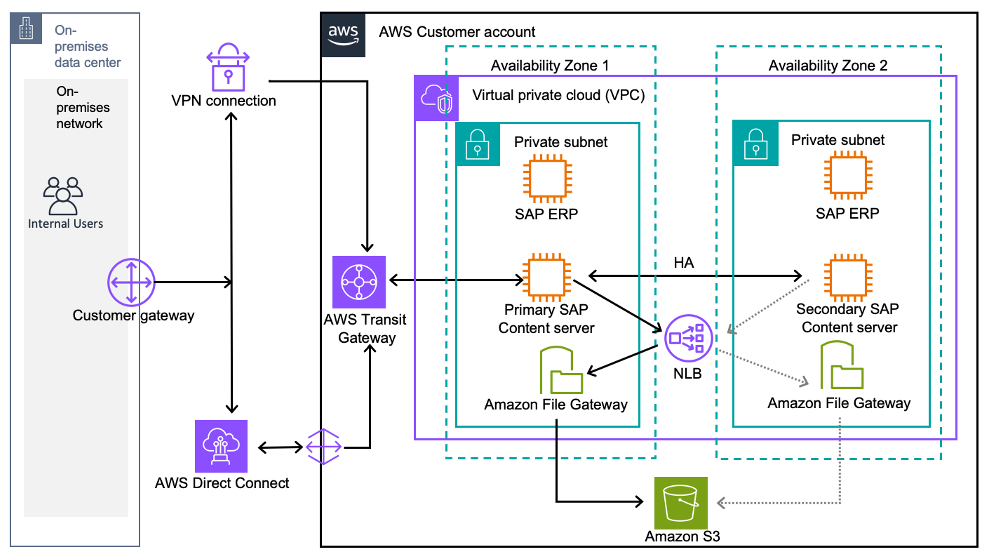
Figure 3: SAP Content Server with High-Availability on AWS native SAP ERP servers
Proposed solution
In Figure 1, the solution architecture implements a HA design where RISE with SAP connects to the S3 File Gateway via SAP Content Server through a Network Load Balancer (NLB). The NLB efficiently routes requests to the primary S3 File Gateway instance from the SAP Content Server, which accesses documents through a local file share connected to an S3 bucket. This architecture leverages an NLB with a Domain Name Service (DNS) name for S3 File Gateway endpoint, ensuring seamless failover capabilities. When a failover occurs, the NLB automatically redirects traffic to the active S3 File Gateway in the secondary Availability Zone (AZ), maintaining continuous access to business documents without disruption to operations.
Below is a step by step guide on installing and configuring two separate S3 File Gateways, creating identical file shares, and ensuring High Availability through a custom pacemaker resource script on Git.
The custom resource implements a pacemaker resource agent for managing S3 File Gateway file shares in a NLB target group. It is designed to provide HA for S3 File Gateway by automatically failing over between instances in different AZs. This architecture leverages NLB’s native target group functionality to redirect the traffic towards S3 File Gateway instances directly across two AZs, instead of using Overlay IP addresses.
Step 1: Install and configure two S3 File Gateways
Begin by installing and configuring two separate S3 File Gateways in different AZs. This setup ensures redundancy and improves data accessibility. Make sure both gateways are mapped to your S3 bucket.

Figure 4: Configuring two S3 File Gateways
Step 2: Create identical file shares
Next, create identical file shares that point to the same S3 bucket. This process allows both Amazon S3 File Gateways to access the same data seamlessly. Ensure that the permissions for these file shares are correctly set to allow access from your applications.

Figure 5: Pointing the S3 File Gateways to the file share
A NLB is required as the entry point to the SAP Content Server. The NLB configuration is shown below
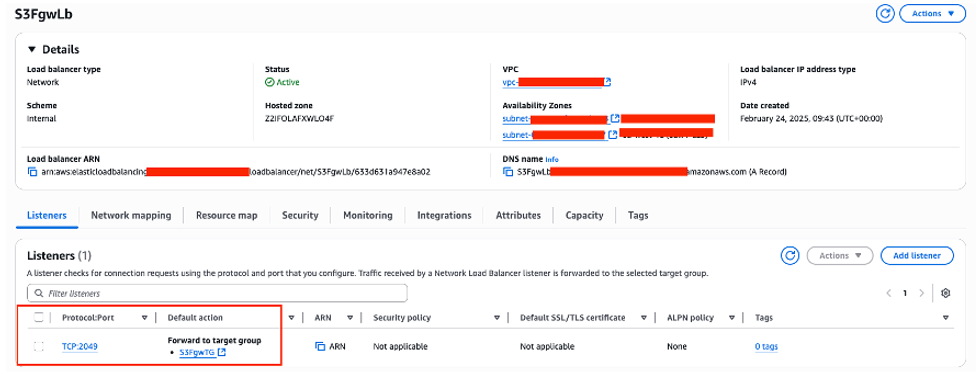
Figure 6: Creating the NLB
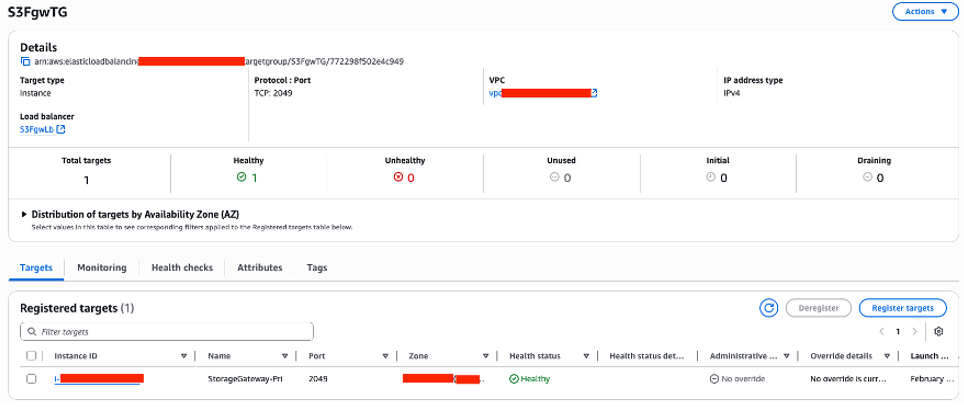
Figure 7: Creating the NLB target group
Refer to this documentation for creating a NLB and an associated target group.
Step 3: Mount NFS share using NLB DNS name
Utilize the NLB DNS name to mount the NFS share on SAP Content Server. This approach provides a single point of access for clients, simplifying connections and improving fault tolerance. Make sure that the NLB is configured to forward requests to both S3 File Gateways.

Figure 8: Amazon S3 File Gateway mount point in the SAP Content Server
Step 4 : Configure the High Availability Cluster Framework software (SLES/RedHat)
Configure the pacemaker cluster following this Git. Once the cluster is successfully configured, check the cluster status via “pcs status”:
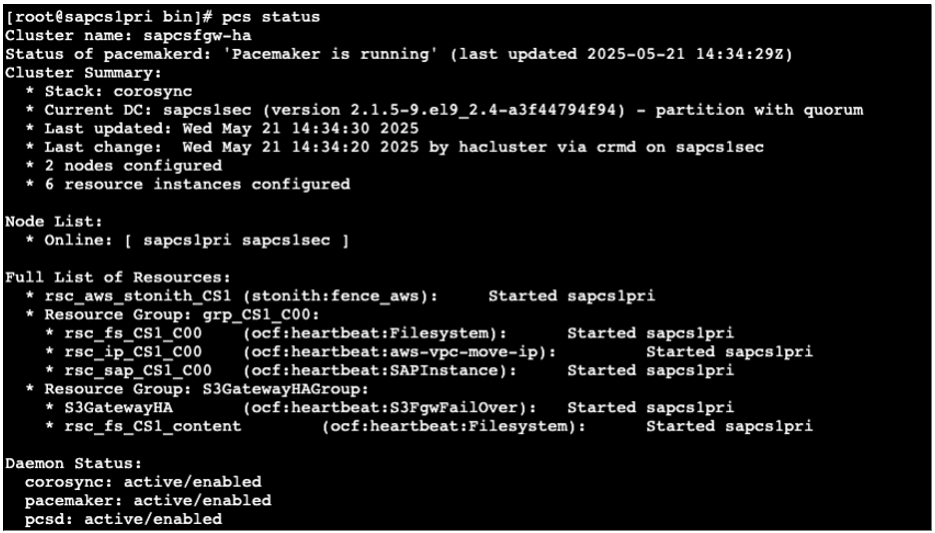
Figure 9: Checking the SAP Content Server HA cluster status
Step 5: Enable EC2 Auto Recovery
Finally, enable EC2 Auto Recovery for your instances (note that this is enabled by default in newly created EC2 instances). This feature automatically recovers instances when system impairments are detected, ensuring that your nodes remain available in their respective AZs. Configure Amazon CloudWatch alarms to monitor instance health and trigger recovery actions as necessary.
By following these steps, you will establish a resilient storage solution that leverages high availability practices, ensuring continuous access to critical data across different AZs.
Step 6: Testing
Before failover:
Using transaction ME22N (Change Purchase Order) as an example, you can attach a PDF document.
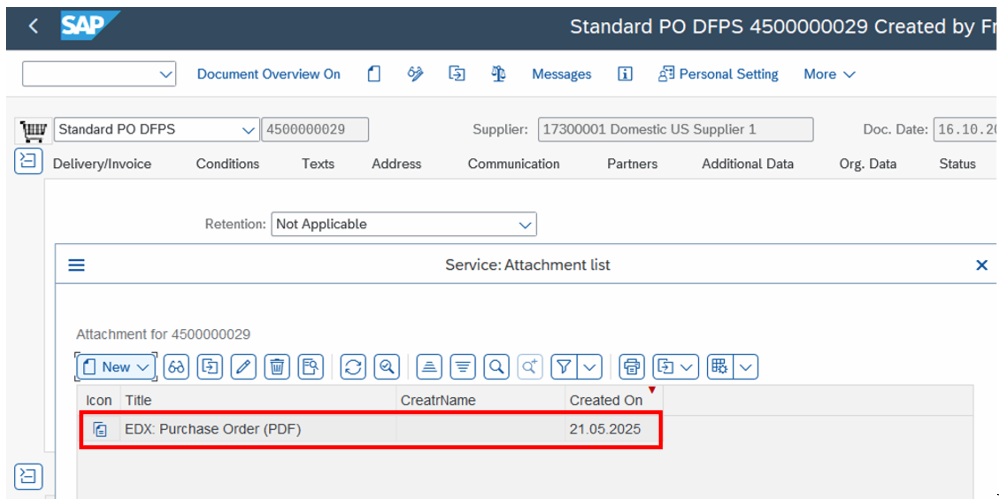
Figure 10: PDF attachment via ME22N
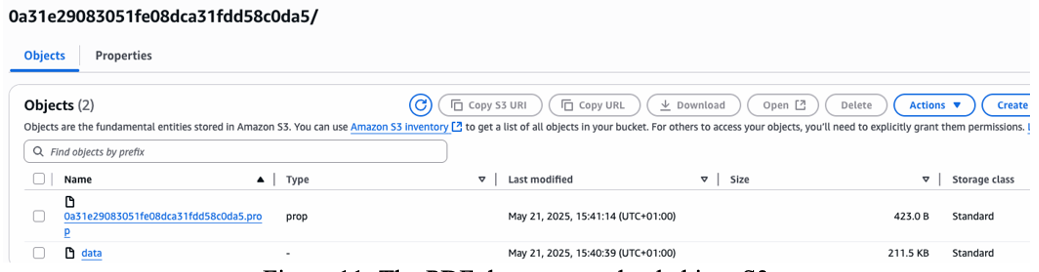
Figure 11: The PDF document uploaded into S3
The SAP Content Server failover to the secondary node can be triggered through several methods. AWS Fault Injection Simulator (FIS) provides a fully managed service to automate high availability (HA) testing by running controlled fault injection experiments on your AWS workloads, allowing you to validate your application’s resilience and identify weaknesses in your disaster recovery procedures before real outages occur. System administrators can initiate the process using pacemaker cluster commands such as “pcs node standby” or “pcs resource move” on the current active node.
Alternatively, the failover can be manually orchestrated or simulated by introducing a fault condition, such as disabling I/O on the /usr/sap mount (for example, via “umount”) on the current SAP Content Server node. During failover, both S3 File Gateway instances remain operational, but the NLB target group registration changes to point traffic to the secondary File Gateway instance. This architecture ensures seamless transition as the NLB redirects traffic to the newly active S3 File Gateway instance, maintaining continuous access to the document management system without disruption to business operations.
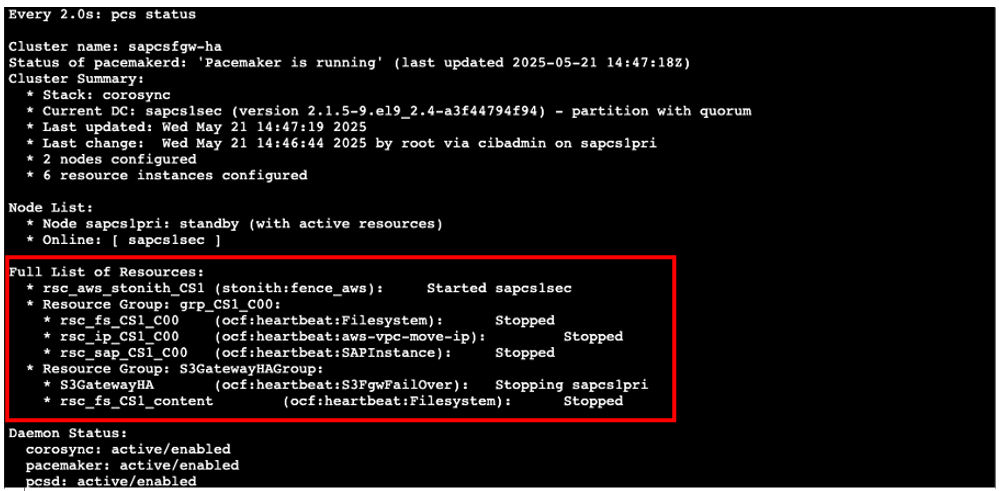
Figure 12: After disruption detected, cluster status is showing primary node being stopped
The cluster resources are starting on the secondary node:
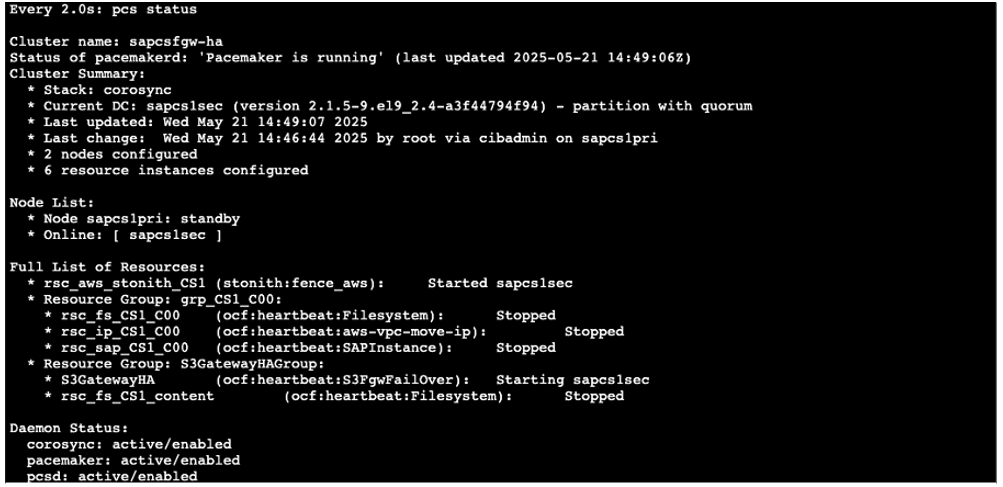
Figure 13: After primary node is stopped, the secondary node is being started by cluster
When Content Server failover successful on the secondary node along with S3 File Gateway, you will see as Figure 14.
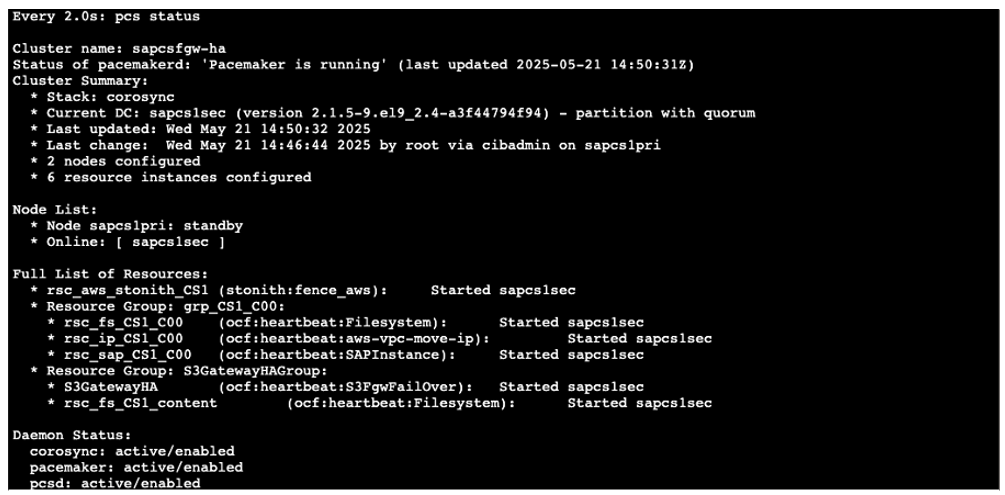
Figure 14: Cluster status showing secondary node started successfully
On the previous primary host, you will see that the S3 File Gateway is no longer mounted.
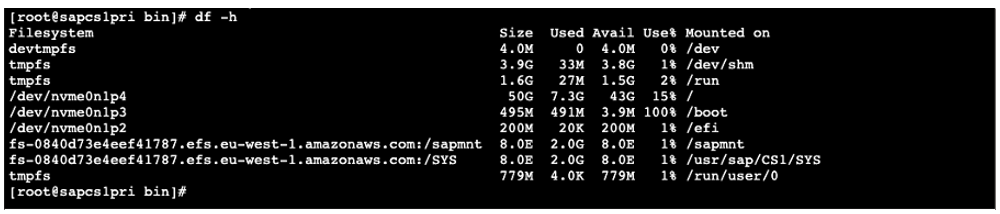
Figure 15: S3 File Gateway mount points no longer mounted on the previous primary node
On the new primary hosts (secondary node), you will see S3 File Gateway is mounted.
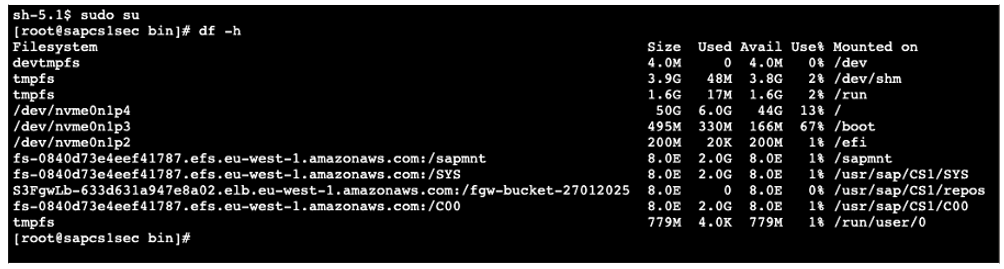
Figure 16: S3 File Gateway mount point mounted on new primary node
Finally, repeat the check via transaction ME22N for SAP Purchase Order attachment after failover to ensure that it is not lost, and you can still access it from SAP ERP.
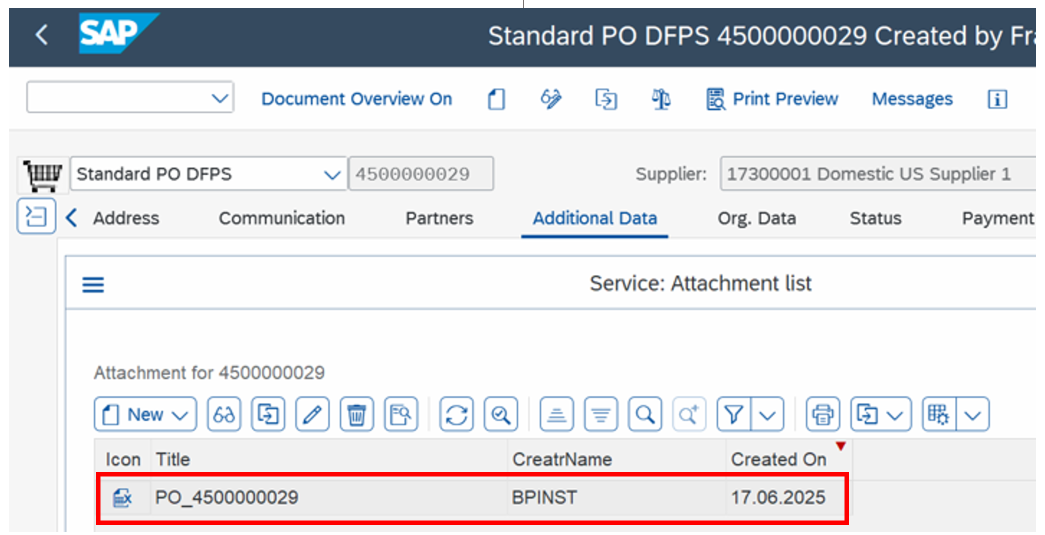
Figure 17: Viewing the PDF attachment in ME22N after the failover
Consideration of S3 and EFS for HA of SAP Content Server
When architecting SAP Content Server on AWS, the choice between Amazon EFS and S3 File Gateway requires careful consideration of their distinct strengths. While both solutions offer high durability and cross-region capabilities, the S3 File Gateway-based architecture stands out primarily through S3’s powerful versioning feature – a critical advantage for data protection. This versioning capability allows for point-in-time recovery of files that have been accidentally deleted or corrupted, a functionality not available in EFS-based solutions where file deletions or corruptions are immediately permanent. Though both services now offer intelligent data tiering for cost optimization and similar cross-region DR capabilities, S3’s versioning essentially provides a built-in backup mechanism, reducing the complexity and cost of maintaining separate backup solutions. For organizations where data recovery and version control are crucial requirements, particularly in compliance-heavy environments where the ability to restore previous versions of documents is essential, the S3 File Gateway architecture offers a more comprehensive data protection strategy. The choice ultimately depends on specific business requirements, with S3 File Gateway being particularly compelling for organizations that prioritize granular data recovery capabilities alongside high availability and performance.
Cost Estimates
In Part 1 of this blog series, we discussed two cost estimates for the S3 File Gateway; the first example for a Content Server database size of 500GB, and the second example for a 5TB database. Extending these pricing estimates to include HA:
- Increasing the SAP Content Server EC2 instance (r7i.xlarge) count from 1 to 2
- Increasing the EBS storage volume (100GB) count from 1 to 2
- Increasing the S3 File Gateway count from 1 to 2
- Adding a NLB
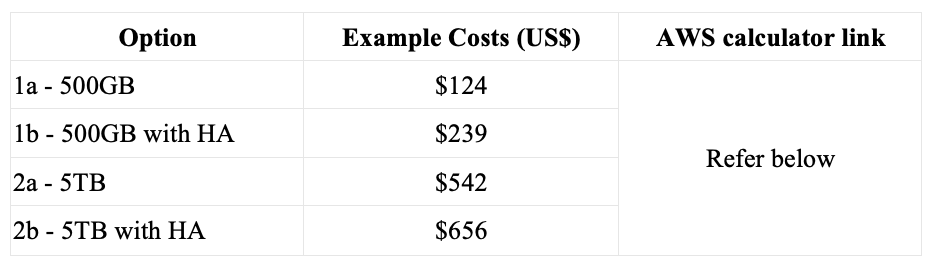 Table 1: Pricing comparison
Table 1: Pricing comparison
AWS Calculator link 1a, 1b, 2a, 2b
For the 5TB database with HA, the cost increases from US$542 to $656. Likewise, for the 500GB database with HA, it increases from $124 to $239, demonstrating that adding HA does not increase the costs significantly.
Please note that the above costs do not include Operating System related subscriptions, you can check these in AWS Marketplace such as SUSE Linux Enterprise Server for SAP Applications and Red Hat Enterprise Linux for SAP.
Conclusion
Implementing a HA solution for SAP Content Servers using S3 File Gateway is essential for organizations aiming to maintain operational resilience and ensure business continuity as mentioned in the Reliability Pillar of the AWS Well-Architected Framework. By following the outlined steps—installing and configuring multiple S3 File Gateways, creating identical file shares, utilizing NLB, utilizing the custom resource scripts for pacemaker in Git, and enabling EC2 Auto Recovery — businesses can create a robust and scalable architecture that withstands potential disruptions.
The proactive approach to managing system performance and resilience not only mitigates the risks associated with downtime but also supports stringent service level agreements. Leveraging AWS’s infrastructure allows organizations to enhance their document management capabilities while ensuring data durability and accessibility. It’s recommended to regularly schedule and automate HA testing using AWS FIS during scheduled downtimes, to maintain and validate your system’s fault tolerance and ensure your disaster recovery mechanisms remain effective as your infrastructure evolves
As businesses increasingly migrate to cloud environments, adopting these HA practices will be crucial in safeguarding critical SAP workloads and driving operational efficiency in the digital age. By investing in a well-architected HA solution, organizations can confidently navigate the complexities of modern IT landscapes, ensuring that their SAP systems remain available and performant.
Join the SAP on AWS Discussion
In addition to your customer account team and AWS Support channels, customers can take advantage of re:Post – A Reimagined Q&A Experience for the AWS Community. Our AWS for SAP Solution Architecture team regularly monitor the AWS for SAP topics for discussion and questions that could be answered to assist our customers and partners. If your question is not support-related, consider joining the discussion over at re:Post and adding to the community knowledge base.
Credits
We would like to thank Ferry Mulyadi, Derek Ewell and Spencer Martenson for their contributions to this blog.








![[속보] SK텔레콤 3분기 영업익 484억원…전년 대비 90.92%↓](https://img.hankyung.com/photo/202510/AD.41815821.1.jpg)


 English (US) ·
English (US) · 