소프트 유도 편향(Soft Inductive Biases)
일반화 프레임워크(Generalization Frameworks)
PAC-Bayes 및 가산 가능한 가설 경계
효과적 차원수(Effective Dimensionality)
기타 일반화 프레임워크
주요 현상
벤다인 오버피팅(Benign Overfitting)
과매개화(Overparametrization)
더블 디센트(Double Descent)
대안적 관점(Alternative Views)
딥러닝의 독특한 요소(Distinctive Features of Deep Learning)
표현 학습(Representation Learning)
보편 학습(Universal Learning)
모드 연결성(Mode Connectivity)
결론 및 전망
딥러닝은 그리 신비롭거나 다르지 않다
 11 hours ago
1
11 hours ago
1
Related

ESBuild를 위한 HMR, 직접 만들기
3 hours ago
0

내가 만난 멋진 SRE (구글 슬라이드)
4 hours ago
0

기술블로그를 책으로, “요즘 우아한 AI 개발” 출간!
5 hours ago
1
Show GN: kubegraph: 실시간 Kubernetes 시각화 툴
7 hours ago
0
아카이브 저장 (Archival Storage)
9 hours ago
1
아마존, 연간 35억 달러 절감을 위한 14,000개 관리직 감축 계획
10 hours ago
0
Wait4X - 서비스가 준비될 때까지 기다려주는 경량 도구
10 hours ago
1
Popular

적십자 홍보대사 이승기 “화려한 경력보다 기부가 더 명예롭죠”
2 weeks ago
37

“본인 계획 명확해” NC 파이어볼러 한재승, 코칭스태프 기대감도 UP
3 weeks ago
27

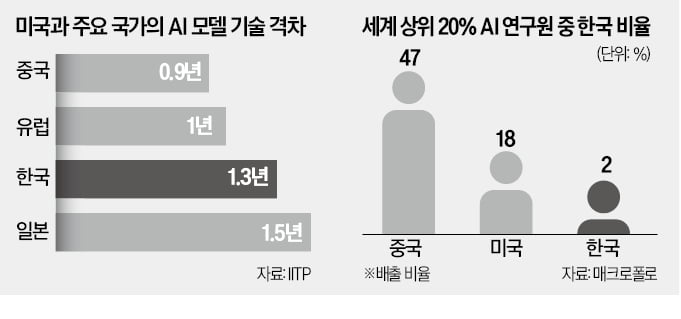
중국에 맞설 '국가대표' 키운다…한국, 1조 '파격 투자'
3 weeks ago
26

‘13년 전 최고 유망주’ ML 잔류할까→‘왼손 셋업’ 조준
3 weeks ago
25

Cloud ERP Offers Unrivaled Data Security
3 weeks ago
25

Business AI with SAP
3 weeks ago
25

How to Prepare for SAP C_BCBAI_2502 Certification?
3 weeks ago
24


 English (US) ·
English (US) · © Clint's Theme Park 2025. All rights are reserved
