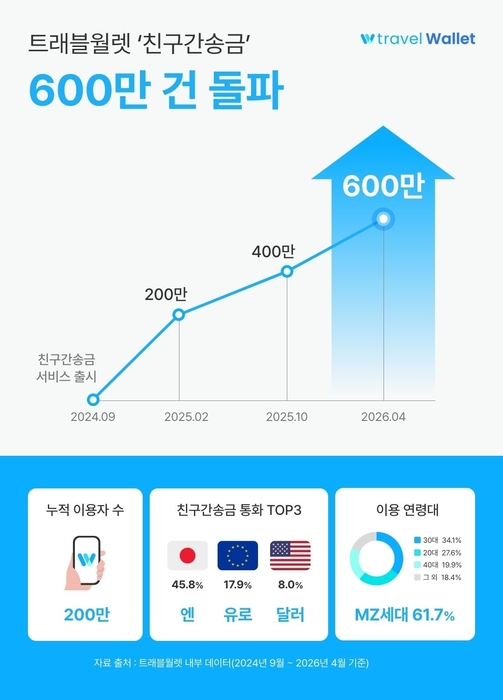
MAI-Code-1-Flash

1 day ago
4
- MAI-Code-1-Flash는 일상 개발자 워크플로우에서 빠르고 효율적인 코딩 지원을 목표로 한 Microsoft의 새 코딩 모델이며, VS Code의 GitHub Copilot 개인 사용자에게 배포 중임
- Microsoft는 이 모델을 GitHub Copilot 하네스에서 직접 학습시켜 실제 개발 환경의 도구·시스템과 더 잘 상호작용하도록 설계함
- 적응형 응답 길이 제어로 단순 요청에는 간결하게 답하고 복잡한 작업에는 더 많은 추론 예산을 쓰며, 최대 60% 적은 토큰으로 더 어려운 문제를 해결함 {p:60}
- Microsoft의 생산 하네스 평가에서 Claude Haiku 4.5보다 4개 핵심 코딩 벤치마크 모두에서 높은 통과율을 보였고, SWE-Bench Pro에서는 51.2% 대 35.2%로 16포인트 앞섬
- 별도 적대적 추론 벤치마크에서는 186문항·34개 범주에서 85.8% 조정 정확도를 기록했지만, Einstellung trap 같은 핵심 적대 범주는 50% 미만 정확도에 머물러 개선 여지가 있음
출시와 배포
- MAI-Code-1-Flash는 빠르고 효율적인 일상 개발자 지원을 위해 만든 Microsoft의 새 코딩 모델임
- Microsoft가 처음부터 끝까지 구축했으며, 깨끗하고 적절히 라이선스된 데이터를 사용함
- GitHub Copilot 개인 사용자의 VS Code에 배포 중이며, 모델 선택기와 기본 Auto picker 아래에서 사용할 수 있음
- 추가 설정은 필요 없고, 배포가 진행되면 GitHub Copilot이 Auto picker를 통해 작업을 MAI-Code-1-Flash로 라우팅하거나 모델 선택기에 직접 표시함
- 피드백은 GitHub Community에서 받을 예정임
개발자 워크플로우 중심 설계
- MAI-Code-1-Flash는 벤치마크 최적화만이 아니라 개발자가 매일 쓰는 생산 워크플로우를 중심에 두고 만들었음
- 생산 환경에서 쓰이는 GitHub Copilot 하네스(harness)로 직접 학습해 에이전트형 코딩 작업에서 주변 도구와 시스템을 다루는 방식을 익히도록 설계함
- 학습 중에는 핵심 소프트웨어 엔지니어링 작업, 저장소 질의응답, 리팩터링, 실제 GitHub Copilot 사용에서 각색한 텔레메트리 기반 작업으로 체크포인트를 평가함
- 학습·평가·생산 환경을 맞추면 오프라인 개선이 실제 개발자 품질로 이어지도록 돕는다는 설계 목표를 가짐
토큰 효율과 응답 방식
- 적응형 솔루션 길이 제어를 학습해 작업 난도에 따라 응답 깊이를 조절함
- 단순 요청에는 간결하게 답하고, 더 깊은 분석이나 더 넓은 코드 변경이 필요한 문제에는 더 많은 추론 예산을 사용함
- 개발자는 유용한 출력을 더 빨리 보기 시작할 수 있음
- MAI-Code-1-Flash는 최대 60% 적은 토큰으로 더 어려운 문제를 해결하며, 지연 시간 감소, 비용 절감, 토큰 대비 수익 개선, 더 부드러운 대화형 워크플로우를 목표로 함
코딩 벤치마크 결과
- Microsoft는 SWE-Bench Verified, SWE-Bench Pro, SWE-Bench Multilingual, Terminal Bench 2에서 MAI-Code-1-Flash와 Claude Haiku 4.5를 같은 생산 하네스로 평가함
- 평가는 작업 성공률과 각 작업 완료에 필요한 평균 솔루션 토큰 수를 측정함
- MAI-Code-1-Flash는 테스트한 4개 핵심 코딩 벤치마크 모두에서 Claude Haiku 4.5보다 높은 통과율을 기록함
- SWE-Bench Pro의 다양한 실제 작업에서는 51.2% 대 35.2%로 16포인트 앞섬
- SWE-Bench Verified에서는 최대 60% 적은 토큰으로 더 어려운 문제를 해결해 정확도와 효율이 동시에 개선될 수 있음을 보임
지시 따르기·추론·한계
- MAI-Code-1-Flash는 표에 나온 모든 벤치마크에서 Claude Haiku 4.5보다 앞섰으며, IF Bench의 정밀 지시 따르기에서는 +28.9로 가장 큰 격차를 보임
- Advanced IF의 루브릭 기반 평가에서는 +14.5로 가장 좁은 격차를 보임
- 강한 지시 따르기 성능은 에이전트형 도구 사용으로도 이어짐
- 수학, 과학, 시각 생성 코딩의 핵심 추론 능력에서도 Claude Haiku 4.5를 앞섬
- 표준 벤치마크는 추론만큼 암기도 보상할 수 있어, Monty Hall 문제를 본 모델은 정답을 맞히지만 상품을 뒤집으면 실패할 수 있음
- Microsoft는 inverted classics, impossible tasks, underdetermined scenarios 같은 적대적 함정을 중심으로 186문항·34개 범주의 벤치마크를 만들었음
- MAI-Code-1-Flash는 이 적대적 벤치마크에서 Claude Haiku 4.5를 전체적으로 넘었고 85.8% 조정 정확도에 도달함
- 추론, 지시 따르기, 불가능한 문제 인식에서 특히 강한 성능을 보였지만, Einstellung trap 같은 핵심 적대 범주는 50% 미만 정확도에 머물러 개선 여지가 남아 있음
-
Homepage
-
Tech blog
- MAI-Code-1-Flash




!['통한의 극장골 실점 패배' 주승진 김천 감독 "뒷심이 부족했다" [전주 현장]](https://image.starnewskorea.com/21/2026/05/2026051714010261496_1.jpg)

![[전화성의 기술창업 Targeting] 〈395〉 [AC협회장 주간록105] 마이클 잭슨 자산과 스타트업 경영](https://img.etnews.com/news/article/2026/05/04/news-p.v1.20260504.773e529e3f474adea55b425cf6daf8c2_P3.jpg)


 English (US) ·
English (US) · 