Intro Knowledge
Short Glossary
Why tokens?
Why not letters?
Why not whole words?
How are the sub-words chosen?
How does the model generate text?
From Tokens to Text
Sampling
Temperature
Presence Penalty
Frequency Penalty
Repetition Penalty
DRY (Don't Repeat Yourself)
Top-K
Top-P (Nucleus Sampling)
Min-P
Top-A
XTC
Top-N-Sigma
Tail-Free Sampling (TFS)
Eta Cutoff
Epsilon Cutoff
Locally Typical Sampling
LLM 샘플링의 모든 것: 더미를 위한 현대적 가이드
 5 hours ago
2
5 hours ago
2
Related

학교 급식비 채무 상환 결정
2 hours ago
0
HN 공개: 약 500ms 지연 시간의 실시간 AI 음성 채팅
3 hours ago
0
VectorVFS - 파일 시스템을 벡터 데이터베이스로 활용
4 hours ago
0
판사, Meta의 AI 저작권 소송을 "다음 테일러 스위프트에 대한 문제"라 언급
4 hours ago
0
Low-Bit LLM을 위한 상용 DRAM에서 구현된 매트릭스-벡터 곱셈
4 hours ago
2
Go 언어에서 Graceful Shutdown을 구현하는 실용적 패턴
5 hours ago
0
경험 많은 LLM 사용자지만, 실제로는 자주 사용하지 않는 이유
5 hours ago
1
AI가 WinDBG를 만났을 때: 2025년 크래시 분석의 미래
5 hours ago
1
Popular
Anubis works
3 weeks ago
74
OpenAI, GPT 4.1 공개
3 weeks ago
71
OpenAI, o3 와 o4-mini 모델 공개
2 weeks ago
53
[Vibe Coding 기업 적응기] Part1: v0.dev와 함께한 3주간의 기록
2 weeks ago
51
"100 Go Mistakes and How to Avoid Them"의 뒷이야기
3 weeks ago
47

How to Create Your First SAPUI5 Application
3 weeks ago
38



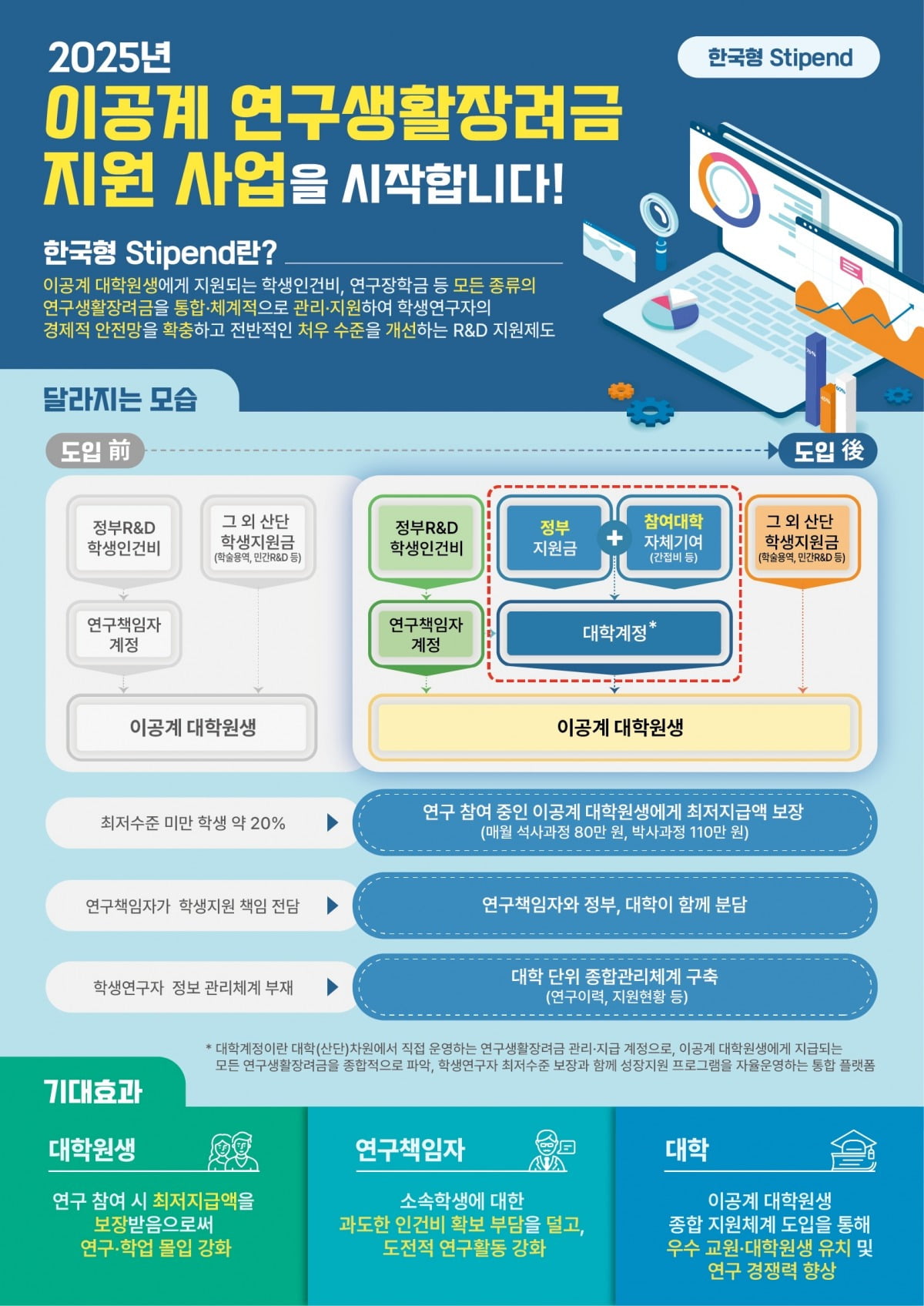
이공계 대학원생, 월 110만원 받는다…'한국형 스타이펜드' 첫걸음
1 week ago
32
 English (US) ·
English (US) · © Clint's Theme Park 2025. All rights are reserved
