- Forge는 자체 호스팅 LLM의 도구 호출을 위한 신뢰성 계층으로, 다단계 에이전트 워크플로우에서 작은 로컬 모델의 안정성을 높이는 데 초점을 둠
- 핵심 기능은 잘못된 도구 호출을 복구하는 rescue parsing, 재시도 유도, 필수 단계 강제, VRAM 인식 토큰 예산, 계층형 컨텍스트 압축으로 구성됨
- 현재 상위 자체 호스팅 구성인 Ministral-3 8B Instruct Q8 on llama-server는 26개 평가 시나리오에서 86.5%, 가장 어려운 티어에서 76%를 기록함
- 사용 방식은 세 가지로, WorkflowRunner로 전체 에이전트 루프를 맡기거나, Guardrails middleware를 기존 오케스트레이션 루프에 넣거나, OpenAI 호환 프록시 서버로 투명하게 적용 가능함
- WorkflowRunner는 시스템 프롬프트, 도구 실행, 컨텍스트 압축, 가드레일을 관리하며, SlotWorker는 공유 GPU 추론 슬롯에 우선순위 큐와 자동 선점 기능을 추가함
- 프록시 서버는 python -m forge.proxy로 실행되며, opencode, Continue, aider 같은 OpenAI 호환 클라이언트와 로컬 모델 서버 사이에 들어가 가드레일을 적용함
- 프록시는 도구가 있는 요청에 합성 respond 도구를 자동 주입해 모델이 일반 텍스트 대신 respond(message="...")를 호출하게 만들고, 응답에서는 이를 제거해 클라이언트에는 정상 텍스트 응답처럼 보이게 함
- 지원 백엔드는 Ollama, llama-server(llama.cpp), Llamafile, Anthropic이며, llama-server는 최고 성능과 제어를, Ollama는 쉬운 설정을, Llamafile은 단일 바이너리 실행을, Anthropic은 프런티어 기준선과 하이브리드 워크플로우를 담당함
- 설치는 pip install forge-guardrails로 가능하고, Anthropic 클라이언트는 pip install "forge-guardrails[anthropic]"로 추가하며, 요구 사항은 Python 3.12+와 실행 중인 LLM 백엔드임
- 평가 하네스는 26개 시나리오로 모델과 백엔드 조합의 다단계 도구 호출 안정성을 측정하며, OG-18 기준 티어와 8개 advanced_reasoning 티어로 나뉨
- 테스트 구성에는 LLM 백엔드가 필요 없는 865개 결정적 단위 테스트와 실제 백엔드 대상 평가 하네스가 포함됨
- Forge 가드레일 프레임워크와 ablation study는 Forge: A Reliability Layer for Self-Hosted LLM Tool-Calling로 출판됐으며, 라이선스는 MIT임
Forge - 가드레일로 8B 모델을 에이전트 작업에서 53%에서 99%로 끌어올리는 도구
 3 weeks ago
24
3 weeks ago
24
Related

Show GN: LOSLES - 금액 자체를 결제 식별자로 사용하는 자동 결제 시스템
1 hour ago
1
오라클, Ampere A1 인스턴스 무료 사용 한도 축소
2 hours ago
3
Nix Flakes와 그에 대응하는 Guix 기능들
3 hours ago
3
Show GN: 다 푼 문제지를 깨끗하게 만들어주는 AI
4 hours ago
3
Moonshot AI가 Kimi K2.7-Code를 출시했습니다.
5 hours ago
4
희토류 없는 전기 모터
5 hours ago
4
Show GN: Codemaru - 내 개발 인생은 어디 티어일까?
6 hours ago
3
Popular

트럼프 “美·나이지리아군, ‘IS 2인자’ 제거… 글로벌 작전 능력 축소”
3 weeks ago
105
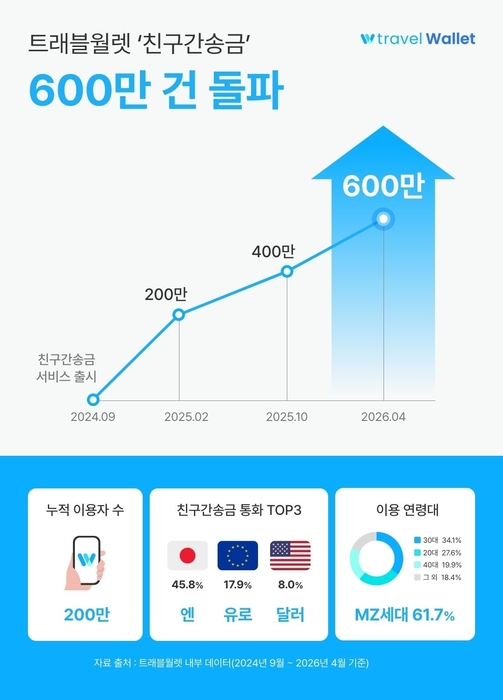
트래블월렛 '친구간송금' 600만건 돌파…2030 해외송금 플랫폼 자리잡았다
4 weeks ago
103
What's new in Chrome from Google I/O 2026
3 weeks ago
100
!['통한의 극장골 실점 패배' 주승진 김천 감독 "뒷심이 부족했다" [전주 현장]](https://image.starnewskorea.com/21/2026/05/2026051714010261496_1.jpg)
'통한의 극장골 실점 패배' 주승진 김천 감독 "뒷심이 부족했다" [전주 현장]
3 weeks ago
100

“트럼프, 中이 원하는 대만 발언 안해…양측 긴장 유지될 것”
3 weeks ago
100
![[전화성의 기술창업 Targeting] 〈395〉 [AC협회장 주간록105] 마이클 잭슨 자산과 스타트업 경영](https://img.etnews.com/news/article/2026/05/04/news-p.v1.20260504.773e529e3f474adea55b425cf6daf8c2_P3.jpg)

테이트 30년, 현대미술사를 바꾼 혁명가의 22세기 미술관론
4 weeks ago
97

테루아와 시간이 빚어낸 예술…뉴질랜드 와인 페스티벌 열린다
4 weeks ago
95
React Doctor — AI가 생성한 React 코드를 정적 분석으로 검증하는 진단 도구
2 weeks ago
92

테슬라, 로봇택시 사고 17건 경위 공개…원격 조종자 개입도 사유?
3 weeks ago
92
 English (US) ·
English (US) · © Clint's Theme Park 2026. All rights are reserved
