이 코드에는 많은 버그가 있음 DiceDB 코드베이스를 보며 디자인에 대한 몇 가지 질문이 있음 이 기술이 실제로 무엇인지 설명하는 문장이 있는지 궁금함 우연의 도구를 데이터 저장 기술의 이름으로 사용하는 것이 재미있음 DiceDB는 무작위 결과를 반환하는 농담 같은 데이터베이스 이름처럼 들림 4vCPU와 num_clients=4에서의 벤치마크 결과가 크게 다르지 않음 DiceDB와 Redis의 성능 비교 GET 요청에 20ms를 소비하는 것이 이해되지 않음 저지연 고처리량 오픈소스 키-값 저장소에 대한 경험이 있는지 궁금함 PubSub의 전달 의미론에 대해 알고 싶음 Hetzner CCX23 기계에서 초당 15655 ops는 인메모리 데이터베이스로서는 느림 Nubmq보다 훨씬 느림Hacker News 의견
DiceDB 출시
 21 hours ago
8
21 hours ago
8
Related

리플링, 스파이 행위로 딜 고소
9 hours ago
1

ESBuild를 위한 HMR, 직접 만들기
14 hours ago
1
내가 만난 멋진 SRE (구글 슬라이드)
14 hours ago
1

기술블로그를 책으로, “요즘 우아한 AI 개발” 출간!
16 hours ago
1
Show GN: kubegraph: 실시간 Kubernetes 시각화 툴
17 hours ago
0
아카이브 저장 (Archival Storage)
19 hours ago
1
아마존, 연간 35억 달러 절감을 위한 14,000개 관리직 감축 계획
20 hours ago
6
Popular

적십자 홍보대사 이승기 “화려한 경력보다 기부가 더 명예롭죠”
2 weeks ago
37

“본인 계획 명확해” NC 파이어볼러 한재승, 코칭스태프 기대감도 UP
3 weeks ago
27


Cloud ERP Offers Unrivaled Data Security
3 weeks ago
26
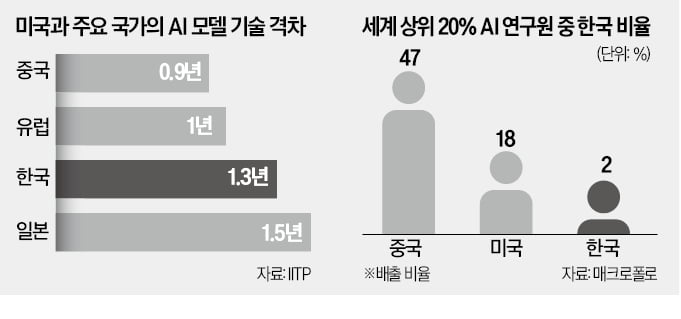
중국에 맞설 '국가대표' 키운다…한국, 1조 '파격 투자'
3 weeks ago
26

Business AI with SAP
3 weeks ago
26


‘13년 전 최고 유망주’ ML 잔류할까→‘왼손 셋업’ 조준
3 weeks ago
25

How to Prepare for SAP C_BCBAI_2502 Certification?
3 weeks ago
25

 English (US) ·
English (US) · © Clint's Theme Park 2025. All rights are reserved
